
在一次回复结束到人类发出下一条消息之间,智能体会空闲多久——而总的空闲时间又主要堆积在哪里?
在一次回复结束到人类发出下一条消息之间,智能体会空闲多久——而总的空闲时间又主要堆积在哪里?
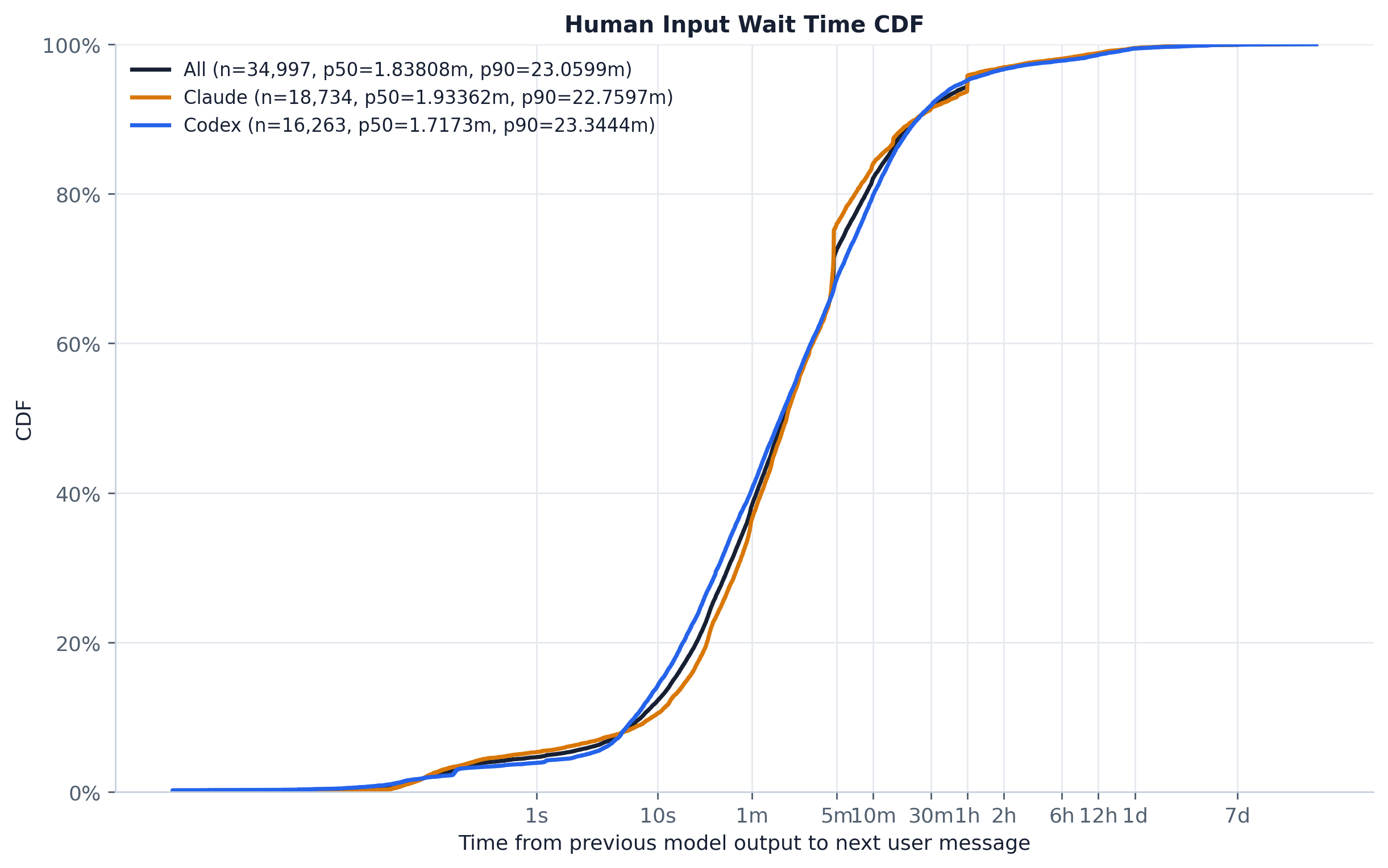
等待分布在主体部分很短,但尾部却横跨七个数量级。人类回复的中位数很快——总体约 ~86s(Claude p50 79s,Codex p50 95s)——但曲线一直攀升到远超一小时之后:总体 p90 约 21 分钟,p99 约 14h,而最长的间隔是一个约 31 天后才被恢复的会话。两个提供商在主体部分走势非常接近,其中 Codex 略微偏右(平均空闲更高,3,260s 对比 Claude 的 2,401s)。读取 5 分钟或 1 小时这两个标记点处的曲线高度,可以看出人类在前缀缓存大概率失效之前作答的频率有多高;长长的右尾是那些被搁置数小时或数天的会话。
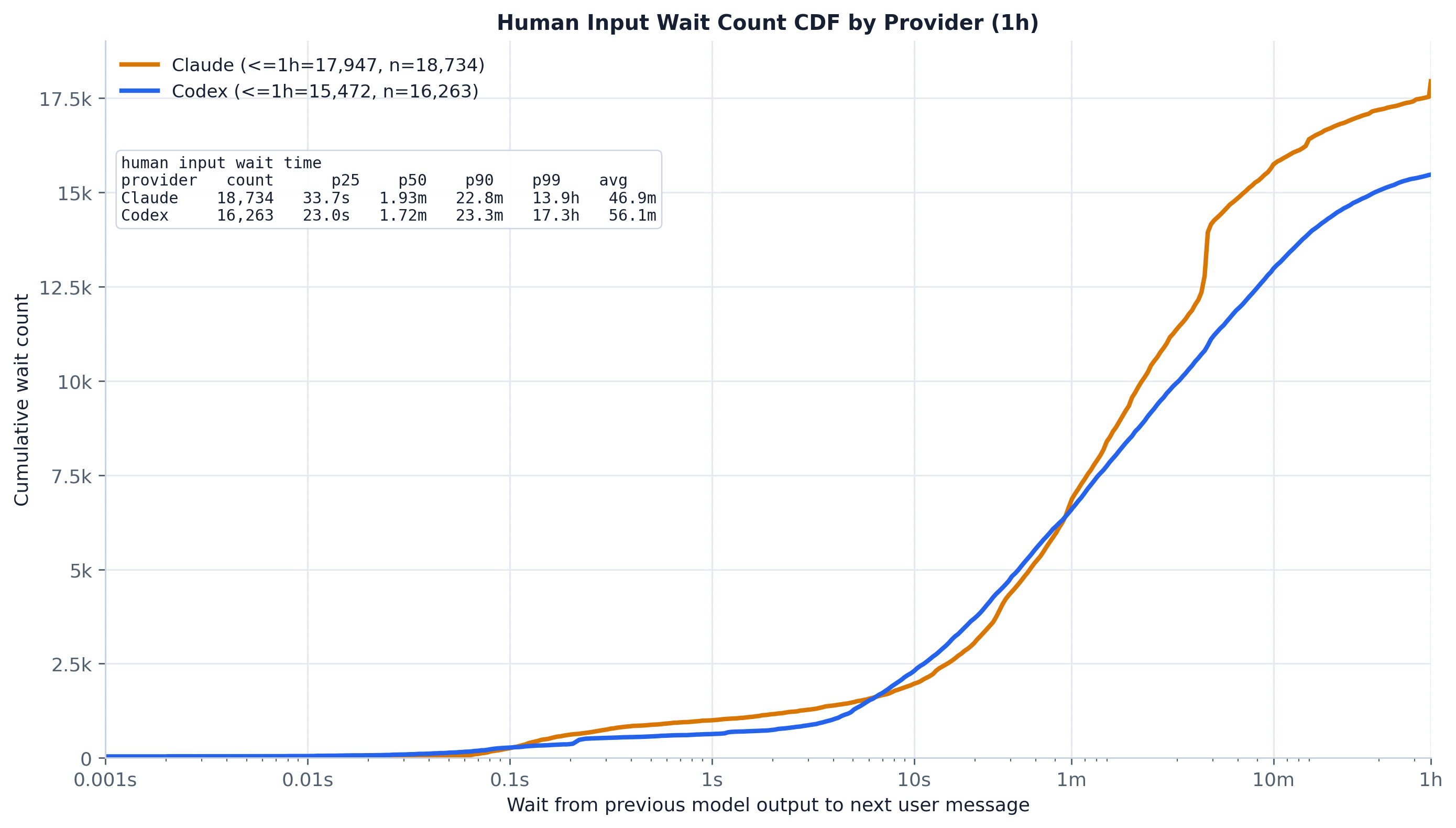
按计数看,大多数空闲间隔都很短——两条曲线都很早开始上升,到 1h 截断处几乎已经饱和。到 5 分钟这个驱逐标记点时,79.6% 的 Claude 等待和 69.8% 的 Codex 等待就已经过去了,而到 1h 时则是 96.4% / 94.9%。所以大致每五次回复中就有一次(Claude)到每三次中就有一次(Codex)耗时超过 5 分钟——长到足以让前缀在下一次请求时大概率已经变冷。Codex 的曲线全程落后于 Claude,与其略长的典型等待一致。图内表格给出了按提供商的分位数和均值。
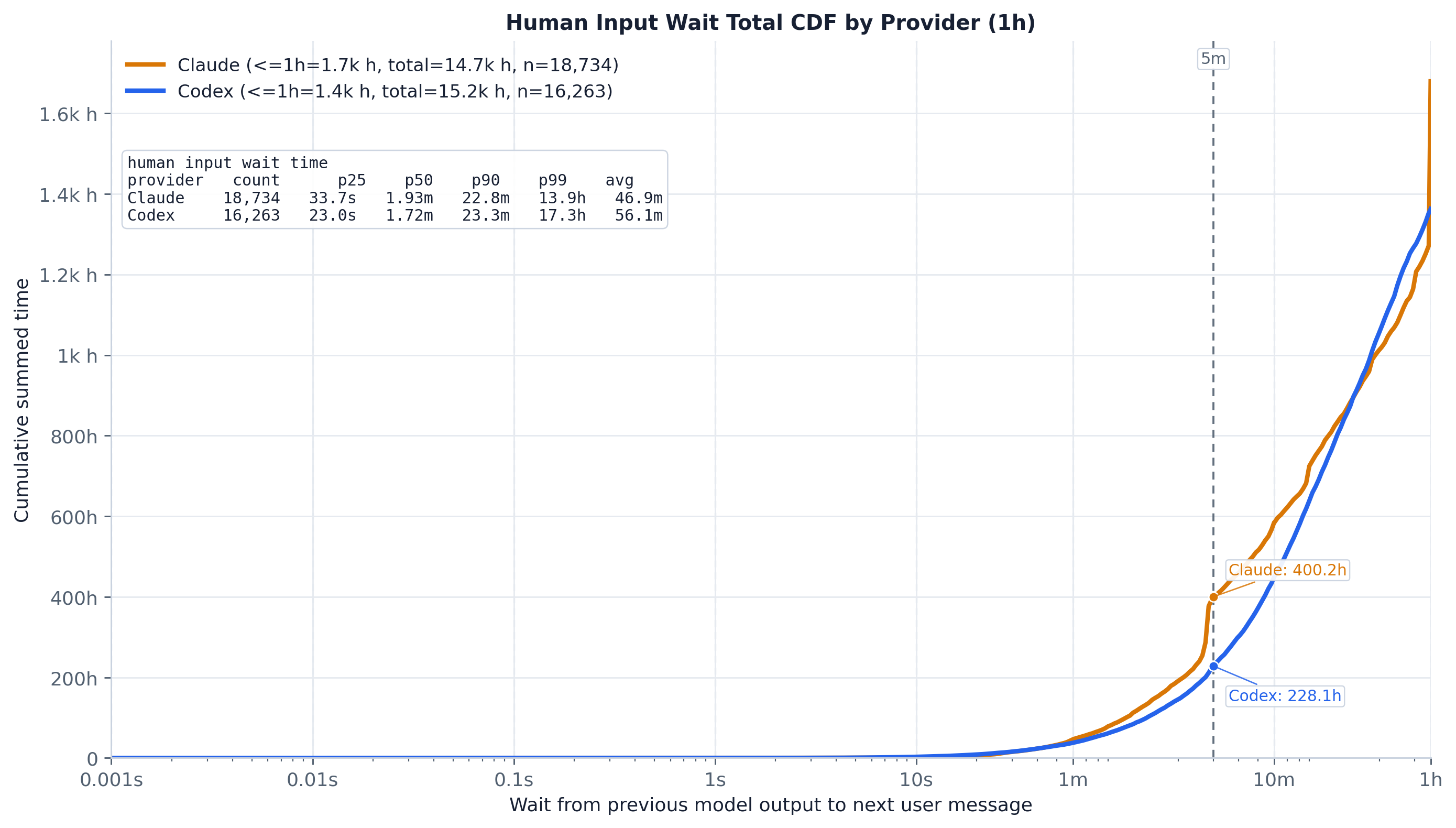
按每个等待的时长加权后,图景被彻底翻转:那些在计数上占主导的短间隔几乎不携带任何时间。到 5 分钟标记点时——此时约 70–80% 的等待已经结束——却只累积了 Claude 总空闲时间的 2.8% 和 Codex 的 1.5%,甚至到 1h 时累计时间占比也只有 11.6% / 8.9%。剩下约 90% 的全部人类空闲时间都存在于长于一小时的等待中,也就是在这条 1h 截断坐标轴的右边缘之外。这条曲线与计数 CDF 之间的巨大差距正是核心结论:极少数非常长的间隔几乎占据了全部的空闲墙钟时间,因此缓存保留决策是由尾部、而非中位数所主导的。
人类输入等待 指的是在同一个会话内,从任意类型的前一个事件到每个
user_message 之间的间隔。它与提供商无关(使用共享的 timing.human_waits_from_event_pairs):这个间隔会跨越非输出事件,例如 Codex 的 usage_report,并且每一条用户消息都计入,而不仅仅是触发轮次的那些。它通过对按 ingestion 顺序排列的智能体步骤进行一次有状态的单遍扫描计算得到(round_pk == 文件顺序),并维护 last_event_at_by_session: {session_id -> datetime}。对于每个步骤,按事件时间顺序:
user_message 事件,若该会话记录了前一个事件的时间戳 prev,则等待时长为 (user_ts − prev).total_seconds();当其严格为正时,将其追加到 "all" 列表以及该步骤的提供商桶中。prev 会更新为每个事件的时间戳(这样连续的 user→user 间隔也会计入),并通过 last_event_at_by_session 在轮次之间延续。这是一个基于 trace 的估计,而不是 serving-engine 计时器;它只反映被记录下来的事件。该等待涵盖了请求之间人类的思考/阅读时间,并排除了模型自身的生成时间。
Note (definition change). 早先这个指标使用的是前一个模型输出 → 触发回复的用户消息,这会丢弃非触发性消息以及 Codex 在输出之后的
usage_report尾部——从而低估了 Codex 的空闲(它在别处以一个无法归因的 “Other” 残差形式浮现出来)。当前这个与提供商无关的定义捕获了全部人类空闲(Claude ≈ 90%,Codex ≈ 94% 的会话墙钟时间)。
本实验以三种方式渲染等待分布,x 轴采用对数时长刻度,count/total 两个面板在 1h 处截断(一条 5 分钟参考线标记了一个可能的缓存驱逐视界):
all 与各提供商;≤ T 的占比;≤ T 的累加空闲时间所占的占比。方法与假设:
all)贡献一个值;CDF、分位数和累加时间分箱都跑在完整集合上。旧的 loader 在这里本来就保留了每一个等待——这个指标从来没有 reservoir 上限——因此迁移是逐值完全一致的。round_pk(ingestion 序号 == 文件顺序),复现了旧的单遍 JSONL loader 在维护会话状态时所依赖的行顺序 tie-break。str(provider) or "<unknown-provider>" 回退逻辑,因此缺失/为空的提供商会落入 <unknown-provider>。CAST(epoch_us(timestamp) AS BIGINT)),并在 Python 中重建为 naive datetime,绝不以原始 TIMESTAMP 取出(native duckdb 会把它编排成 datetime,而 duckdb-wasm 会编排成字符串)。两个同时区 datetime 之差恰好等于 naive-microsecond 之差,因此这些等待与迁移到 DuckDB 之前的结果逐比特一致。plot.py 是一条跑在共享 trace DuckDB 之上的 query→shape→plot 流水线:
load_human_input_wait_seconds_by_provider(con) —— 唯一的数据加载代码。它按 round_pk ingest 顺序拉取每个步骤的 timing_events(event_type + epoch-microsecond 时间戳),以及来自 rounds 的每个步骤的 (session_id, provider),然后运行上文那个有状态的扫描,返回 {"all": [...], provider: [...]}。返回的是完整的按提供商列表,没有采样。timing.human_waits_from_event_pairs(...) —— 共享的、与提供商无关的核心(从 artifacts/utils/timing.py 导入):给定一个会话的 (event_type, timestamp) 对以及延续过来的前一事件时间,它按时间顺序扫描,并返回正的 前一事件→user_message 等待。同一个 helper 也支撑了基于 row-dict 的消费方(trace_loader、overview_summary),因此每条路径计算出的等待都完全相同。_epoch_us_to_datetime(...) —— 从 epoch-microseconds 重建一个 naive datetime。ordered_human_wait_items / human_wait_summary_row / plot_human_input_wait_cdf /
write_human_input_wait_summary —— 构造叠加 CDF 和 summary CSV(与迁移前的脚本一致)。cdf.py helper 生成
(plot_count_cdf_by_provider / plot_cumulative_duration_cdf_by_provider 及其 write_*
对应项)—— matplotlib/CSV 行为保持不变。main() —— 接入标准的 trace_db CLI(--db | -i/--input | -o/--output-dir),并嵌入自包含的 PNG sidecar。数据层(解析、surrogate key、schema)位于 artifacts/utils/trace_db.py;参见
artifacts/utils/DB_SCHEMA.md。
# default merged trace, output next to this README
uv run python artifacts/human_in_the_loop/human_input_wait/plot.py
# a specific trace (materialized to a temp DuckDB cache on first use)
uv run python artifacts/human_in_the_loop/human_input_wait/plot.py -i trace/sample.jsonl
# a prebuilt DB (run_all.py's build-db step passes this), into a chosen dir
uv run python artifacts/human_in_the_loop/human_input_wait/plot.py --db /tmp/trace.duckdb -o /tmp/out
human_input_wait_cdf.png —— 单坐标轴等待 CDF,叠加 all 与各提供商,图例中带有
n/p50/p90。human_input_wait_count_cdf_by_provider.png / .csv —— 按提供商的计数 CDF,基于等待阈值
(等待 ≤ T),含每个分箱及累计的计数/占比。human_input_wait_total_cdf_by_provider.png / .csv —— 按提供商的累加空闲时间 CDF,含每个分箱的
秒/小时以及累计时间占比。human_input_wait_summary.csv —— 按组(all + 各提供商)的 count、mean、p50/p90/p95/p99
以及 max(单位为秒)。每张 PNG 都把本 README、上述 CSV,以及绘图代码(plot.py + 共享的
artifacts/utils/ 模块)以压缩文本 chunk 的形式嵌入。可用
python artifacts/utils/png_sidecar.py extract <png> 解包。