
在从本步骤新追加的 token 中去除上一步骤的模型输出之后,每个步骤实际新增的外部上下文增长(新的用户/工具内容 + framing)有多少?
在从本步骤新追加的 token 中去除上一步骤的模型输出之后,每个步骤实际新增的外部上下文增长(新的用户/工具内容 + framing)有多少?
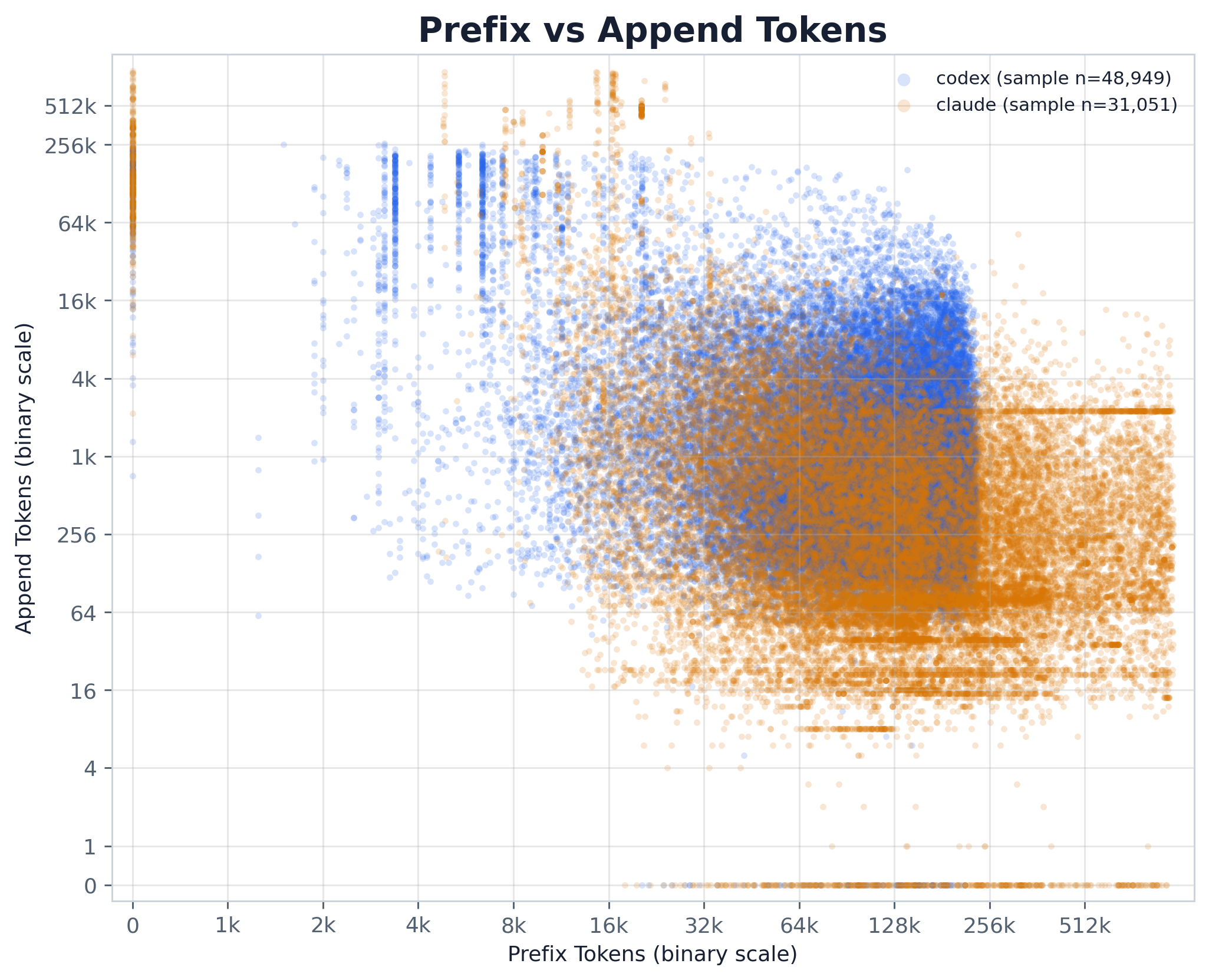
一张以 base-2 对数轴绘制的前缀-vs-调整后追加散点图,每个提供商一个着色系列。x 轴是当前步骤复用的缓存前缀;y 轴是它的调整后追加——在减去上一步骤重放的输出之后新计费的 token。要点:
raw_append vs adjusted_append,以及减法把追加减到零的 clipped_after_subtract 占比)。--pair-sample-size 个点),因此它传达的是联合结构,而非精确密度;各提供商的分位数请读 CSV。上一个 assistant 响应通常会被重放进下一次 prompt,因此它出现在下一个步骤的 newly_append_tokens(缓存写入 / 新计费切片)之内。将其减去即可分离出真正新增的内容。该指标是一种在**会话内(within a session)应用的相邻步(adjacent-step)**策略:按顺序遍历每个会话的各步骤,并将每个步骤与紧邻其前的那个步骤比较(round_index 恰好相差 1)。
对于每一个这样的 (previous, current) 对,本实验在 current 上推导:
max(0, newly_append_tokens − prior-step output proxy),外加中间量 signed_adjusted_append(裁剪前)以及一个 clipped_after_subtract 标志,用于标记那些被减为负值的对。方法与假设:
--subtract-policy(默认 claude-and-gpt55) 决定哪些对要做减法。只有 Claude 与 Codex gpt-5.5 会把它们的上一次输出——包括推理——带入下一步骤的追加,因此只有那些 previous 行会被减去。gpt-5.4 及更早的 Codex 模型不会把推理带入下一步,因此减去它会导致过度计数并把追加虚假地裁剪到 0;这些行保持**原始(raw)**不变。all 会对每个提供商/模型都做减法,仅为对比而保留。--subtract-output(默认 total) 决定从选中的行中减去哪个量:total 减去完整的 output_tokens(visible + reasoning),对 Claude/gpt-5.5 是正确的,因为它们会重放推理;visible-for-codex 则对 Codex 改为减去 output_tokens − reasoning_output_tokens。缓存记账的依据见 ../../../docs/prompt_cache_accounting.md。session_id 以首次出现(文件)顺序分组,再按 round_index 稳定排序,因此并列时保持文件顺序。共享 DuckDB 的 surrogate key ingest_seq(= round_pk)正是该文件顺序,所以以 ORDER BY ingest_seq 拉取并在 Python 中分组,可逐字节复现会话内行顺序以及会话访问顺序。(n−1)·q),与 np.percentile 的默认行为一致。--pair-sample-size,默认 80k)。由于采样器被保留并按文件顺序(ingest_seq)馈入,它保留与迁移前 loader 完全相同的点——在固定 trace 上,散点图逐字节不变。plot.py 是一条建立在共享 trace DuckDB 之上的 query→shape→plot 流水线:
load_adjusted_pairs(con, *, subtract_output, subtract_policy, sample_size, seed) — 以 ORDER BY ingest_seq 拉取 step 级列,丢弃 provider/session_id 非字符串或 round_index 非整数的行(旧 loader 的有效性门控;在 pinned-schema DB 中这些就是 NULL 行),分组进保留文件顺序的 rows_by_session,按 round_index 对每个会话做稳定排序,然后遍历相邻对。它返回经 reservoir 采样的 (provider, prefix, adjusted_append) 散点样本、完整的各 provider:metric summary_values 列表,以及一个统计 Counter。output_proxy(...) / should_subtract_previous_output(...) — --subtract-output 量与 --subtract-policy 行选择,与迁移前保持不变。plot_adjusted_prefix_append(...) — 前缀-vs-调整后追加散点图(二进制 token 轴、各提供商系列),matplotlib 行为不变。write_summary_csv(...) — 各 provider/metric 的分位数 CSV,使用旧版 median/percentile/fmt 辅助函数,使数值与迁移前的运行完全一致。main() — 接入标准的 trace_db CLI(--db | -i/--input | -o/--output-dir)并嵌入自包含的 PNG sidecar。数据层(解析、surrogate key、schema)位于 artifacts/utils/trace_db.py;参见 artifacts/utils/DB_SCHEMA.md。
# default merged trace, output next to this README
uv run python artifacts/llm_generation/adjusted_prefix_append/plot.py
# a specific trace (materialized to a temp DuckDB cache on first use)
uv run python artifacts/llm_generation/adjusted_prefix_append/plot.py -i trace/sample.jsonl
# a prebuilt DB (run_all.py's build-db step passes this), into a chosen dir
uv run python artifacts/llm_generation/adjusted_prefix_append/plot.py --db /tmp/trace.duckdb -o /tmp/out
常用 flag:--subtract-policy(claude-and-gpt55 / all)、--subtract-output(total / visible-for-codex)、--pair-sample-size(散点子采样,默认 80000)、--max-groups(最多绘制的提供商数,默认 8)。
写入 -o(默认即本文件夹):
prefix_vs_adjusted_append_sample.png — 前缀 vs 调整后追加散点图(reservoir 子采样)。prefix_vs_adjusted_append_summary.csv — 在全部对上计算的各 provider/metric 分位数(count、median、p90、p95、p99、min、max),涵盖 raw_append、previous_output、signed_adjusted_append、adjusted_append、subtracted_pair 以及 clipped_after_subtract 指标。该 PNG 是自包含的——它嵌入了本 README、汇总 CSV,以及绘图代码(plot.py + 共享的 artifacts/utils/ 模块)。可用 python artifacts/utils/png_sidecar.py extract <png> 解包。