
问题。 trace 观测到的解码速度与 Codex 残余 TTFT 估计值,如何随单步输入上下文长度而变化?
问题。 trace 观测到的解码速度与 Codex 残余 TTFT 估计值,如何随单步输入上下文长度而变化?
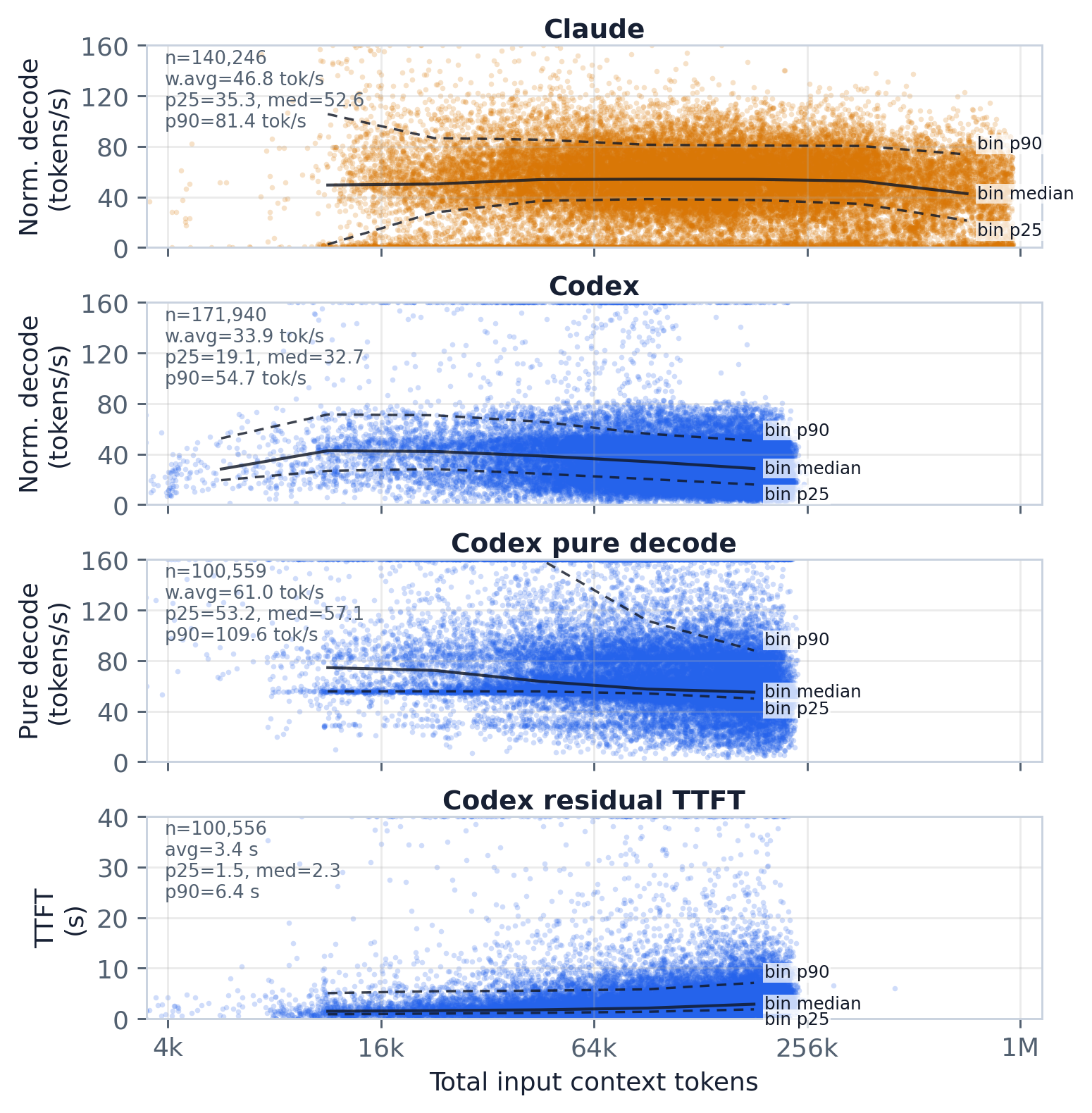
这组堆叠面板(即论文中的 fig:context_decode_speed)将 trace 观测到的计时数据相对于总输入上下文绘制,并在单步点云之上叠加分箱 p25/median/p90 趋势。核心结论是:上下文越长,生成越慢,但在每个上下文长度上单步散布都很宽。Claude 的分箱归一化解码速度中位数在其大部分区间内保持在 50–54 tokens/s 附近,仅在最长上下文处下滑,在约 740k 输入 token 处降至约 43 tokens/s。Codex 则呈现更明显的斜率:其分箱中位数从 12k–23k 输入 token 处的 ~43 tokens/s 降至 185k 附近的 ~29 tokens/s。仅 Codex 的面板将各组成部分分离开来——纯解码速度中位数从 12k 处的 ~74 tokens/s 降至 185k 附近的 ~55 tokens/s,而残余 TTFT 中位数在同一区间内从 ~1.5s 攀升至 ~2.9s。因此,单凭上下文长度并不能解释这些方差;调度、模型版本、输出形态以及后端状态显然也都有贡献。
每个点对应一个智能体步骤,且该步骤具有正的输出 token 数、正的总输入 token 数,以及正的可观测生成时段(observable generation span)。上下文长度取自 input_tokens_total,若该总量缺失则回退为 prefix_tokens + newly_append_tokens。
归一化解码速度定义为:
output_tokens / observable_generation_span_seconds
其中可观测时段是从首个模型输出事件之前(含同时刻)的最近一个输入事件(user_message 或 tool_result)开始,到最后一个模型输出事件(reasoning、text 或 tool_call)为止。该定义与论文宏(paper macros)所用的归一化解码速度中位数定义一致。它是 trace 观测到的时间,而非 serving-engine 内部的解码计时器。
对于 Codex,本图还报告两个精确推理 token 估计值(exact-reasoning-token estimates),仅限于推理后时段(post-reasoning span)至少有 0.1 秒的步骤。纯解码速度(Pure decode speed)是可见或结构化输出 token(output_tokens - reasoning_output_tokens)除以从推理标记/结束(reasoning marker/end)到最后一个非推理模型输出事件(text 或 tool_call)的时段。残余 TTFT(Residual TTFT)定义为:
input_to_reasoning_end_seconds - reasoning_output_tokens * aggregate_post_reasoning_decode_latency
其中 aggregate_post_reasoning_decode_latency 是在所有符合条件的精确推理 Codex 步骤上计算的、按 token 加权的 Codex 推理后解码延迟。这些定义与论文宏中对 Codex 推理后解码速度和残余 TTFT 的定义一致。速度面板上显示的 w.avg 标签是按 token 加权的平均吞吐量(sum(tokens) / sum(seconds)),从而避免了对单步比值取算术平均时的离群点敏感性。
散点图为提升可读性而对点做确定性抽样,但汇总(summary)与分箱分位数(bin-quantile)CSV 使用全部符合条件的步骤。Y 轴上限由 --max-speed-tokens-per-second(默认:160 tok/s)、--max-pure-decode-tokens-per-second(默认:160 tok/s)以及 --max-ttft-seconds(默认:40 s)限定。超出绘制范围的值绘制在坐标轴边界处。绘制的 x 轴起点为 --min-context-tokens(默认:4096 tokens)。Codex 的纯解码与残余 TTFT 面板要求 post_reasoning_output_seconds >= --min-codex-post-reasoning-seconds(默认:0.1)。
uv run python artifacts/llm_generation/context_decode_speed_scatter/plot.py \
--db trace/syfi_coding_trace.duckdb \
--min-codex-post-reasoning-seconds 0.1
context_decode_speed_scatter.png / .pdf — 带分箱 p25/median/p90 趋势的堆叠散点面板。context_decode_speed_summary.csv — 各提供商的上下文与归一化速度分位数。context_decode_speed_bins.csv — 各提供商按二进制上下文长度分箱的速度分位数。context_decode_speed_codex_timing_summary.csv — Codex 纯解码与 TTFT 分位数。context_decode_speed_codex_timing_bins.csv — Codex 纯解码与 TTFT 按二进制上下文长度分箱的分位数。