
上一步的输出必须重新出现在下一步的 prompt 里——但出现在哪儿?是被折进缓存前缀(output-cached),还是被踢出缓存、作为重新计费的追加再次发送(output-resend)?本实验先铺陈这两种核算方案,再测量每个模型实际采用的是哪一种。
上一步的输出必须重新出现在下一步的 prompt 里——但出现在哪儿?是被折进缓存前缀(output-cached),还是被踢出缓存、作为重新计费的追加再次发送(output-resend)?本实验先铺陈这两种核算方案,再测量每个模型实际采用的是哪一种。

上一步的输出可以以两种方式进入下一步的 prompt(即论文的 fig:output_attribution)。在 (a) output-cached 下,serving 系统保留它在解码期间产生的 KV,因此上一步的整套组成——前缀、追加和输出(10 + 2 + 4 = 16 个单位)——折进下一步的缓存前缀,下一步随后只再加上它自己新鲜的追加和输出。在 (b) output-resend 下,只有上一步的前缀和追加被缓存(10 + 2 = 12);上一步的输出被踢出缓存,作为下一步计费追加的一部分重新发送(4 + 1 = 5),所以判据就是:被重新发送的输出使下一步的追加长于上一步的输出。我们靠各自的不变量来区分这两种情形——output-cached 让下一步的前缀增益跟踪上一步的输出,output-resend 让下一步的追加把它吸收掉。在上一步输出 ≥2k token 上按模型应用(即论文的 fig:model_merged_output_attribution),Claude 与 gpt-5.5 落在 output-resend(≈98–99% append-side,prefix-close 接近零),而 gpt-5.4 是 output-cached(约 82% prefix-close,仅约 13% append-side)。可能的成因是 PD 分离式 serving 中的 KV 缓存池管理:output-cached 必须把解码产生的 KV 回传到共享存储,而 output-resend 让解码保持只读、直接把上一步的输出重新预填充一遍。下面的散点图与 ranked 面板就是这个检验,按场景以及 ≥2k / ≥4k 的输出阈值划分。
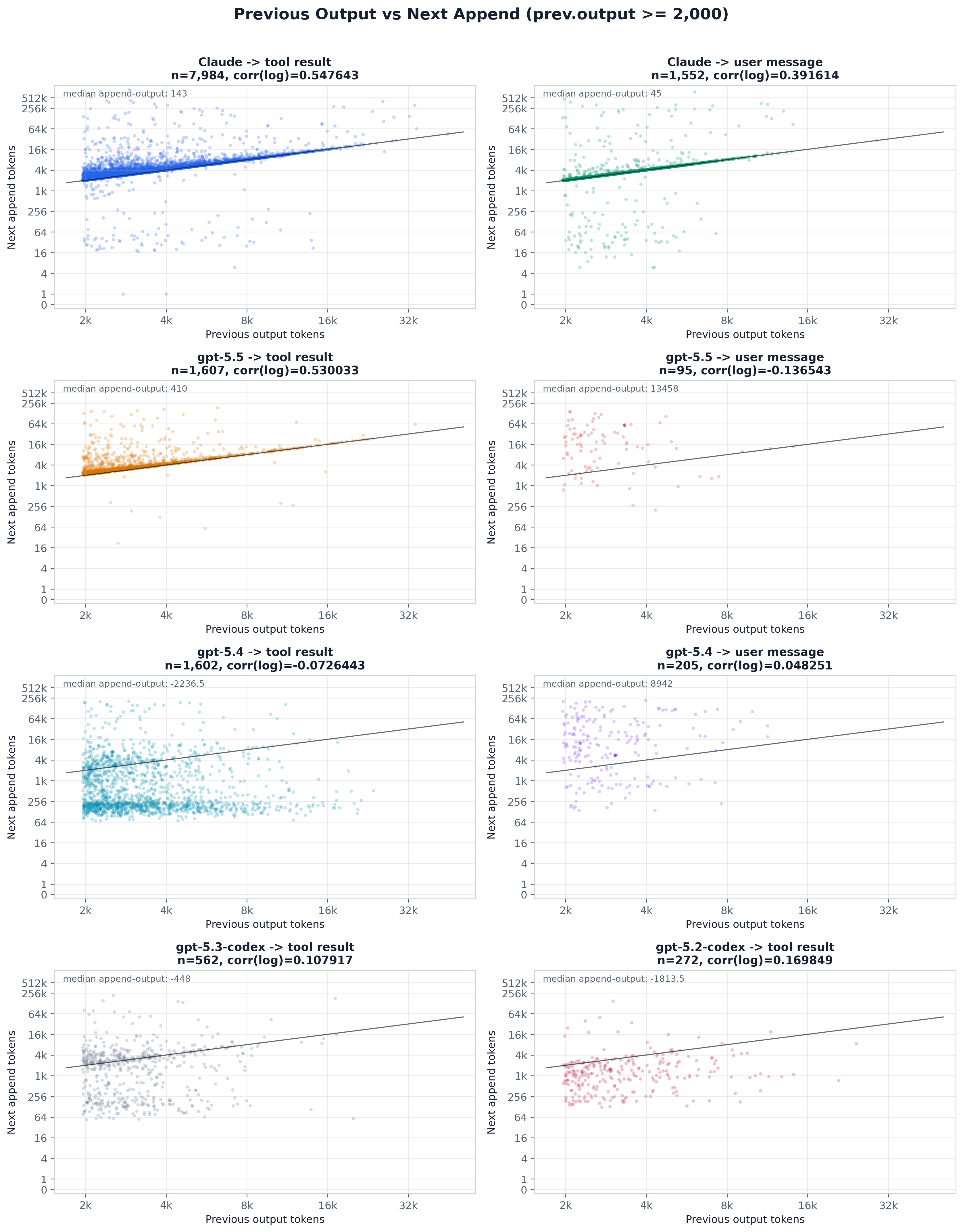
每个场景一个散点面板(上一步输出 ≥ 2k),坐标轴为以 2 为底的对数:x = 上一步的输出 token,y = 下一步新追加的 token,并带 y = prev.output 对角线以及每个面板的 corr(log) 和中位 append − output。紧贴对角线的点就是 resend 信号——上一个响应几乎一对一地重新出现在下一步的追加里。Claude 和 gpt-5.5 面板正落在线上(中位 append − output 接近 +140 和 +410 token),即 resend 指纹;gpt-5.4 远在线下(中位追加远小于它的输出),与那段输出被缓存进前缀而非重发相符。该面板是每个场景的子采样,因此读它是看形状,量级请到 summary CSV 中确认。
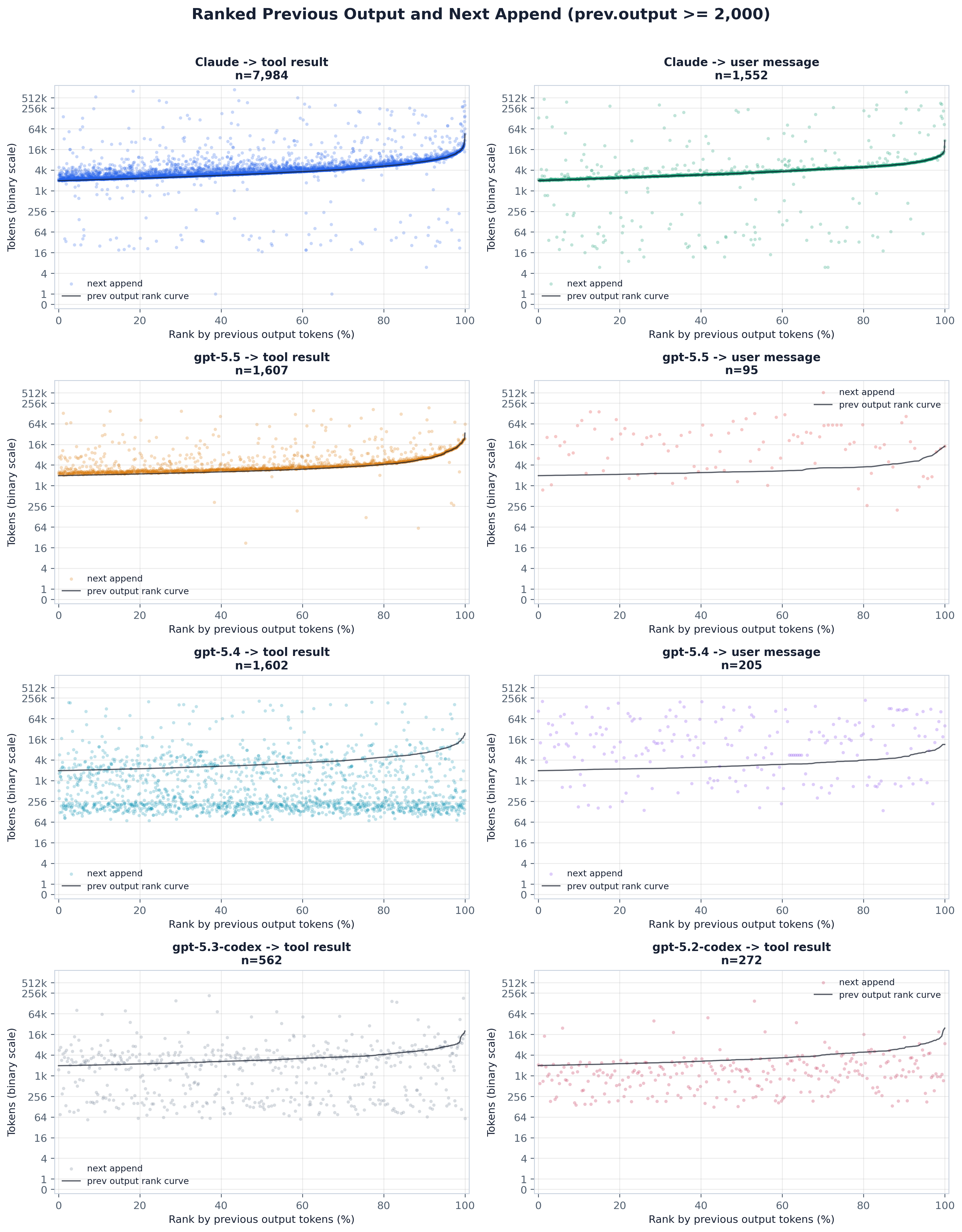
同一份 ≥2k 输出的数据,做排序:x = 按上一步输出的分位数 rank,黑色曲线是排序后的上一步输出扫描,散点是每个 rank 处的下一步追加。它把”追加与输出同升”(曲线与点云同步——resend 模型)与一个 level-shift 间隙(点云位于扫描之下——cached 模型)区分开来,并且对那条压缩了原始散点的重尾 token 分布具有鲁棒性。
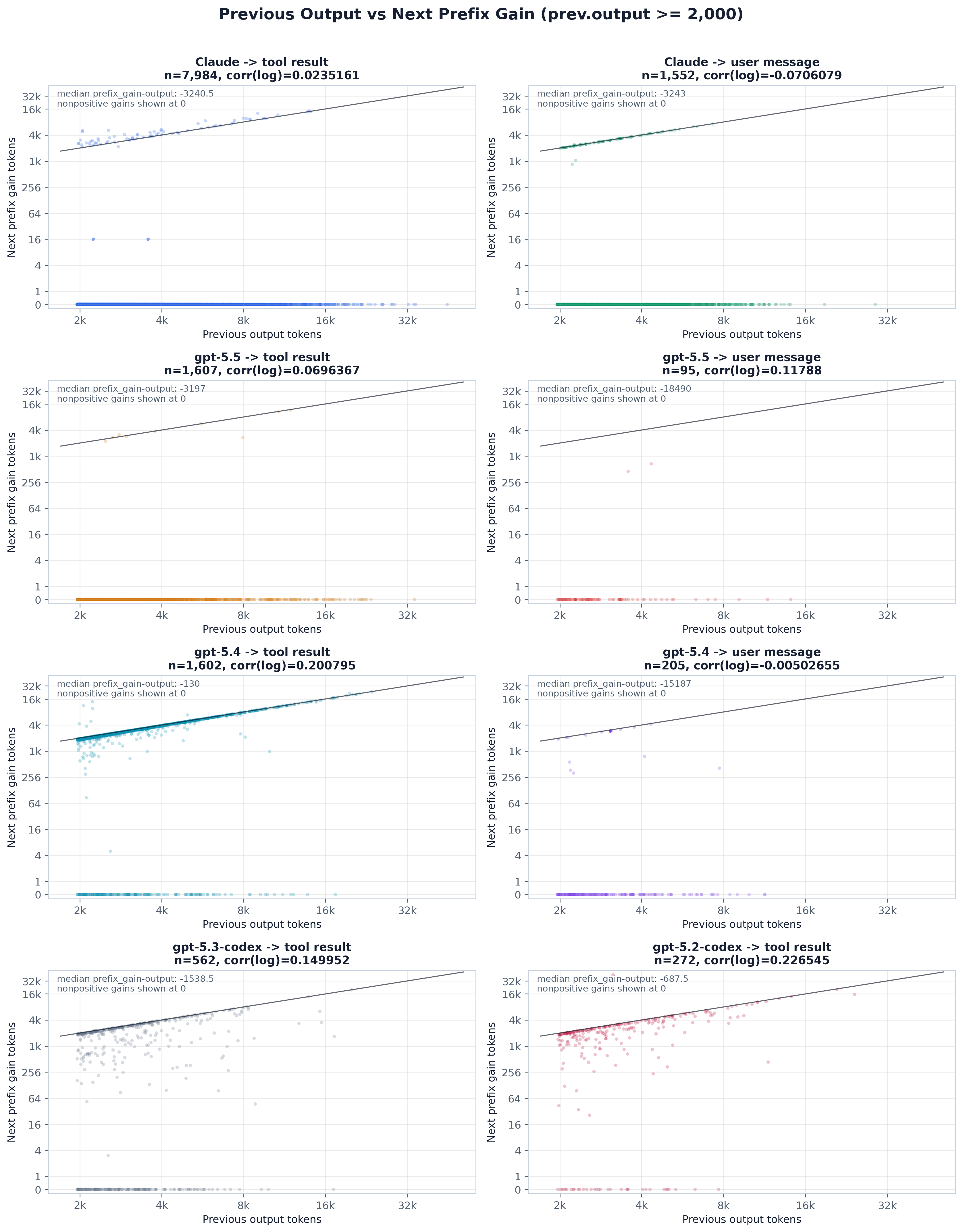
x = 上一步输出,y = 下一步的前缀增益(current.prefix_tokens − previous.input_tokens_total,非正的增益画在 0 处),并带 y = prev.output 对角线。落在对角线上的点是 cached 一侧——上一步的输出被吸收进了下一步的缓存前缀,而不是作为追加重新计费。gpt-5.4 正是在这里分离出来:它的前缀增益跟踪上一步的输出(中位前缀增益约 2.6k,对应约 3.0k 的输出),即 output-cached 的特征,而 Claude 和 gpt-5.5 把它们的增益钉在 0,意味着上一步的输出并没有让缓存前缀增长,而是落进了追加。
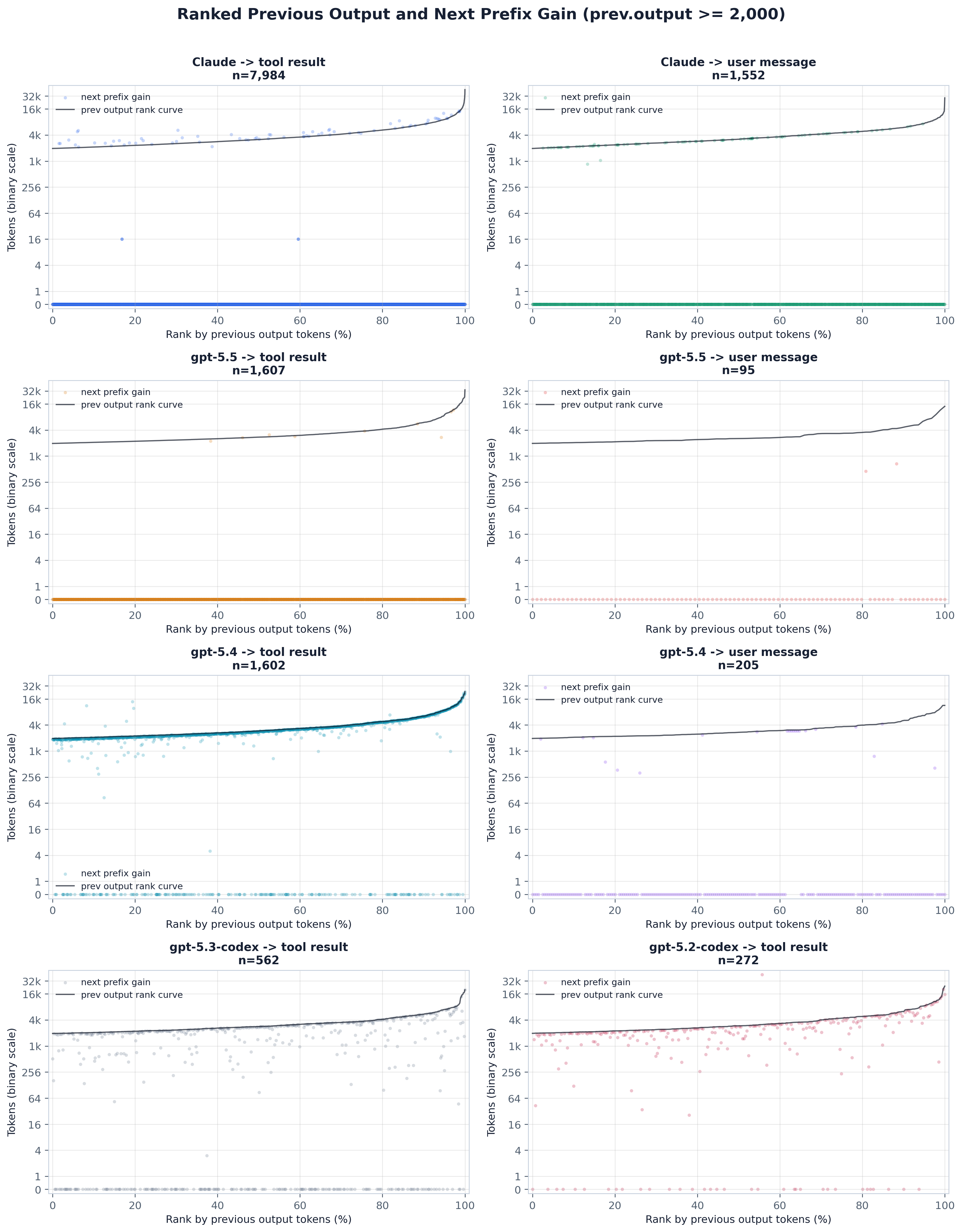
前缀增益的排序对应版(≥2k 输出):x = 按上一步输出的分位数 rank,黑色曲线 = 排序后的上一步输出扫描,散点 = 每个 rank 处的下一步前缀增益。它读起来像追加 rank 网格,但针对的是缓存前缀一侧,使人容易看出在哪些输出量级上、上一个响应开始落到前缀上——对 gpt-5.4 很显著(点云跟踪扫描),对 resend 模型则不存在(点云钉在低处)。
上一个 assistant 响应通常会被重放进下一个 prompt。本实验通过比较同一会话内相邻的智能体步骤来追问它落在哪里:把 prev.output_tokens 与下一步的 newly_append_tokens(重新计费的那一片)以及下一步的 前缀增益(prefix gain)(current.prefix_tokens − previous.input_tokens_total)做比较。它检验 ../../../docs/prompt_cache_accounting.md 中的重放假说:上一个响应一般会出现在下一步的追加/缓存写入中。
方法与假设:
(provider, session_id) 分组,按 (round_index, first-event timestamp) 排序,每个步骤都与排序后紧随其后的那个步骤配对。(与 adjusted_prefix_append 不同,这里的配对是按序相邻,而非严格的 round_index 差 1。)reasoning/text/tool_call,否则回退到它首次观测到的时间戳)到当前步首次观测到的时间戳,这段间隔必须 ≥ 0 且 ≤ --max-gap-seconds(默认 240)——这会剔除跨对话或过期的配对。previous 步的 input_tokens_total 或 output_tokens 非正的配对会被跳过。tool_result vs user_message)来划分配对:Claude、gpt-5.5、gpt-5.4、gpt-5.3-codex、gpt-5.2-codex。max(512, 0.10·prev_output):prefix_close(前缀增益 ≈ 上一步输出)、prefix_rejects_output(前缀增益远低于上一步输出)、append_can_contain_output,以及 append_side_pair(= reject ∧ can-contain)。每个场景的 prefix_close_pct / append_side_pair_pct 驱动一个 decision 标签(prefix_side / append_side / mixed / not_sure)以及一个 decision_strength。output_tokens。对 Codex 而言,输出包含推理,因此可见输出的代理量 output_tokens − reasoning_output_tokens 在方法注记里作为上下文报告(携带的 prev_reasoning 按对记录),但绘图所用的量是 output_tokens。--min-output-tokens,默认 2000 4000)剔除小输出噪声;每个阈值 N 产出一整套图 + summary。percentile,(n−1)·q);统计不做任何采样。(provider, session_id) 以首次出现(文件)顺序分组,再对每个会话按 (round_index, first_timestamp) 做稳定排序,使并列项保持文件顺序。共享 DuckDB 的代理键 ingest_seq(= round_pk)正是那个文件顺序,因此用 ORDER BY ingest_seq 拉取并在 Python 中分组,可逐字节复现每个会话内的行顺序与会话访问顺序。这对散点图很重要:每个场景子采样按 prev_output 的稳定排序在并列时保持成对的追加顺序,而那个追加顺序由会话访问顺序驱动。plot.py 是一条建立在共享 trace DuckDB 之上的 query→shape→plot 流水线:
load_pairs(con, *, max_gap_seconds)——以 ORDER BY ingest_seq 拉取 step 级列,并以 ORDER BY round_pk, event_index 拉取每步的计时事件(时间戳为 epoch_us 整数,再重建为 naive datetime 以保证 native/wasm 一致的序列化),剔除 provider/session_id 非字符串、round_index 非整数或无观测时间戳的行(旧 loader 的有效性门槛;在固定 schema 的 DB 里它们就是 NULL 行),按 rows_by_session 分组并保持文件顺序,对每个会话按 (round_index, first_timestamp) 稳定排序,然后遍历相邻配对并施加间隔门槛。返回 Pair 列表。first_timestamp(...) / last_model_output_timestamp(...)——一个步骤首次观测到的与最后一个模型输出的时间戳,基于其计时事件按 event_index 顺序计算,语义与迁移前一致。prefix_close、prefix_rejects_output、append_can_contain_output、append_side_pair、assignment_label)以及 scenario_groups()——未变。plot_scatter_grid / plot_rank_grid / plot_prefix_gain_scatter_grid /
plot_prefix_gain_rank_grid——四个图族;sampled_pairs(...) 是每个场景的散点抽稀(在稳定的 prev_output 排序上做确定性的、按 rank 分层的 np.linspace)。write_summary(...)——每个场景的 decision/quantile CSV,使用旧的 percentile / fmt 辅助函数,使数值与迁移前的运行完全一致。main()——接入标准的 trace_db CLI(--db | -i/--input | -o/--output-dir),保留自定义的 --max-gap-seconds / --min-output-tokens / --max-points-per-scenario flag,并嵌入自包含的 PNG sidecar。数据层(解析、代理键、schema)位于 artifacts/utils/trace_db.py;参见 artifacts/utils/DB_SCHEMA.md。
# default merged trace, output next to this README
uv run python artifacts/llm_generation/output_append_assignment/plot.py
# a specific trace (materialized to a temp DuckDB cache on first use)
uv run python artifacts/llm_generation/output_append_assignment/plot.py -i trace/sample.jsonl
# a prebuilt DB (run_all.py's build-db step passes this), into a chosen dir
uv run python artifacts/llm_generation/output_append_assignment/plot.py --db /tmp/trace.duckdb -o /tmp/out
有用的 flag:--max-gap-seconds(配对间隔上限,默认 240)、--min-output-tokens(每个阈值一套图,默认 2000 4000)、--max-points-per-scenario(每个场景的散点/rank 子采样,默认 6000)。
写入 -o(默认本文件夹),每个 --min-output-tokens 阈值 N 一套:
output_vs_next_append_scatter_min{N}.png——上一步输出 vs 下一步追加散点网格。ranked_output_vs_next_append_min{N}.png——排序后的上一步输出 / 下一步追加网格。output_vs_prefix_gain_scatter_min{N}.png——上一步输出 vs 下一步前缀增益散点网格。ranked_output_vs_prefix_gain_min{N}.png——排序后的上一步输出 / 下一步前缀增益网格。output_append_assignment_summary_min{N}.csv——每个场景的 count、decision、
decision_strength、对数输出相关性、prefix_close / prefix_reject /
append_can_contain_output / append_side_pair / unassigned 各百分比,以及中位数 /
p10 / p90 的 token 分位数(在全部配对上计算)。每个 PNG 都是自包含的——它内嵌了本 README、summary CSV 以及绘图代码
(plot.py + 共享的 artifacts/utils/ 模块)。用
python artifacts/utils/png_sidecar.py extract <png> 解包。