
模型每个智能体步骤生成多少 token,这一分布又如何随提供商 / 模型而不同?
模型每个智能体步骤生成多少 token,这一分布又如何随提供商 / 模型而不同?
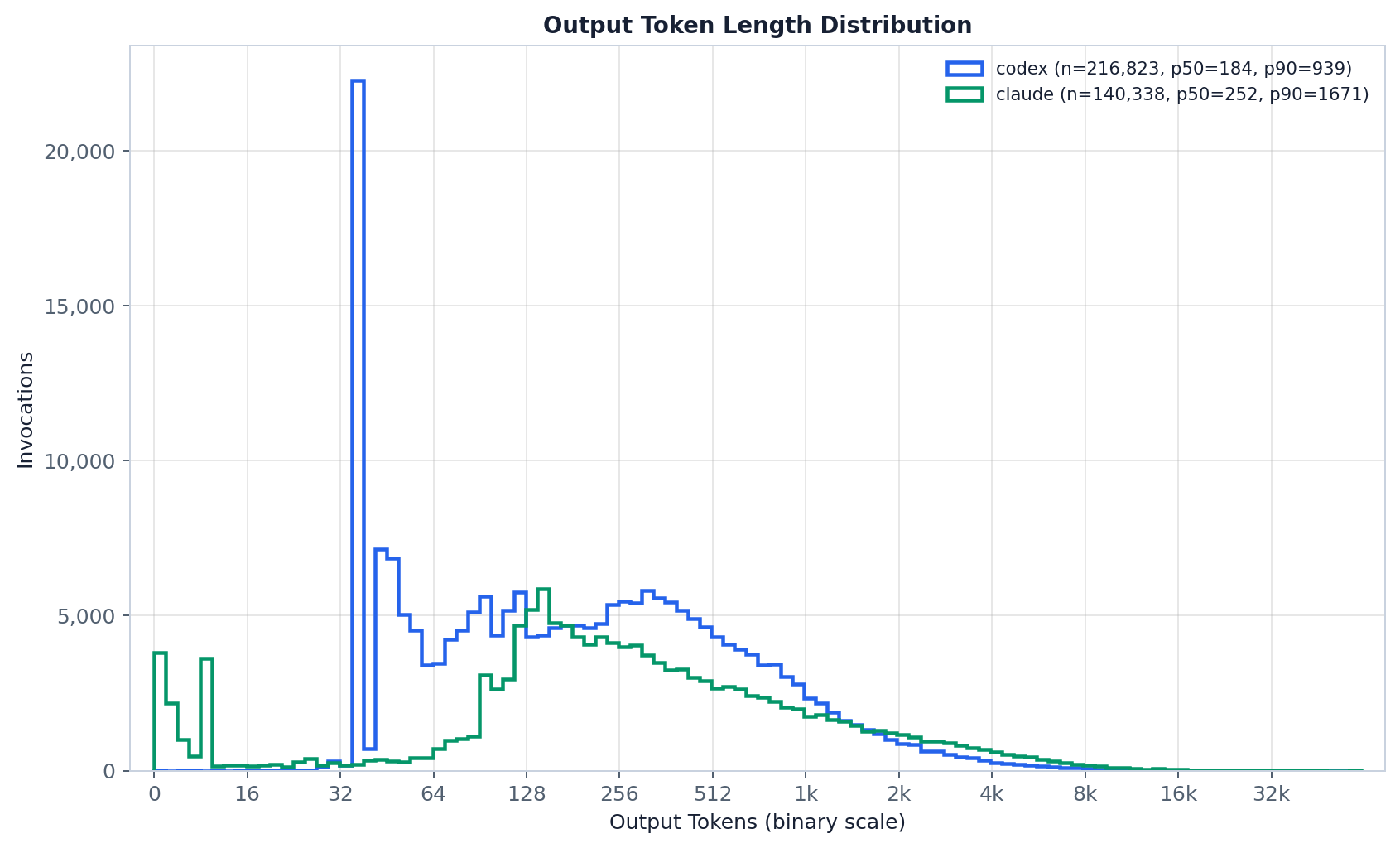
完整的每步输出分布(即论文的 fig:output_tokens):两个提供商都堆积在低百位 token 区间——Claude 中位 252,Codex 184——而曲线强烈右偏,只有一条细尾的长生成触及各组的 max。如此短的输出是工具循环的预期结果:一次完整回复被切成约 8 个工具调用步骤,因此大多数步骤只吐出下一个调用的参数,而非一段长回答。Codex 还多出一个鲜明的第二特征——一处非常短(约 40-token)生成的显著尖峰——这源于它大量使用 write_stdin 来等待一个正在运行的命令,或发送 Ctrl+C 去中断它。请把两条曲线并排看,而不要把某一个数字叠加比较:Codex 把推理 token 折进 output_tokens 而 Claude 不会,因此 Codex 更重的尾部可能反映的是推理而非更多可见输出,而 <unknown-*> 桶(若存在)标记的是来源缺失的步骤。
trace 为每个智能体步骤记录 output_tokens——该步骤生成的 token 数。本实验绘制该计数的分布,按提供商(或模型,或 provider:model)分组,置于以 2 为底的对数 token 轴上,并写出按组的分位数。
方法与假设:
output_tokens 非 null 且 >= 0 的步骤都为其组(以及合成的 all 组)贡献一个值。这与旧 loader 的 allow_zero 数值规则一致——零输出步骤被保留,负值(从未观测到)被丢弃。output_tokens 包含推理 token;对 Claude 它是 message 级的输出计数。因此跨提供商时这些分布并非严格地同口径——请就各提供商自身来解读。sampled 列恒为 False,且 sample_count 等于完整的 count。(在任何低于旧 200k 上限的 trace 上——例如 trace/sample.jsonl——旧路径本就已精确,因此那里的迁移是逐值一致的。)group_key() 的 "<unknown-provider>" / "<unknown-model>" 回退,通过 SQL COALESCE 实现,因此缺失/为空的提供商或模型值会落入一个显式的 <unknown-*> 桶,而不是被丢弃。plot.py 是一条建立在共享 trace DuckDB 之上的 query→shape→plot 流水线:
load_metric_by_group(con, *, column, group_by)——唯一的数据加载代码。它拉取每一个非 null、非负的 output_tokens 值及其组标签(一次无 GROUP BY 的 SQL 扫描),返回 {group_label: MetricStats} 加上一个 all 组。不采样。MetricStats——对该组完整 np.ndarray 值的一层薄封装,暴露精确的 count / min / max / mean 以及 percentiles(...)(NumPy 线性插值,与旧的分位数方法一致)。selected_groups(stats, max_groups)——被绘制的组:除 all 之外的全部,最大者优先,受 --max-groups 限制。plot_output_tokens(...)——在共享的二进制 token 轴上渲染阶梯式直方图
(formatters.token_axis_*、style.*);matplotlib 行为与迁移前脚本一致。write_output_token_summary(...)——按组的分位数 CSV。main()——接入标准的 trace_db CLI(--db | -i/--input | -o/--output-dir),加上 --group-by 和 --max-groups,并嵌入自包含的 PNG sidecar。数据层(解析、代理键、schema)位于 artifacts/utils/trace_db.py;参见 artifacts/utils/DB_SCHEMA.md。
# against the shared DuckDB built by run_all (no per-script re-parse)
uv run python artifacts/llm_generation/output_tokens/plot.py --db /tmp/trace.duckdb
# or straight from a JSONL trace (materialized to a temp cache on first use)
uv run python artifacts/llm_generation/output_tokens/plot.py -i trace/sample.jsonl
# group by model instead of provider, show more groups
uv run python artifacts/llm_generation/output_tokens/plot.py -i trace/sample.jsonl --group-by model --max-groups 12
output_tokens_distribution.png——按组的输出 token 直方图,置于以 2 为底的 token 轴上;图例报告每个组标签。output_tokens_summary.csv——按组的分位数:count, min, p50, p90, p95, p99, max, mean,外加 sample_count(= count)和 sampled(恒为 False,因为统计是精确的)。该 PNG 是自包含的:它把本 README、output_tokens_summary.csv 以及绘图代码作为压缩文本块内嵌其中。用 python artifacts/utils/png_sidecar.py extract <png> 解包。