
对每个智能体步骤,输入 prompt 有多大,以及它如何在复用的缓存前缀与必须付费的新追加 token 之间拆分?
对每个智能体步骤,输入 prompt 有多大,以及它如何在复用的缓存前缀与必须付费的新追加 token 之间拆分?
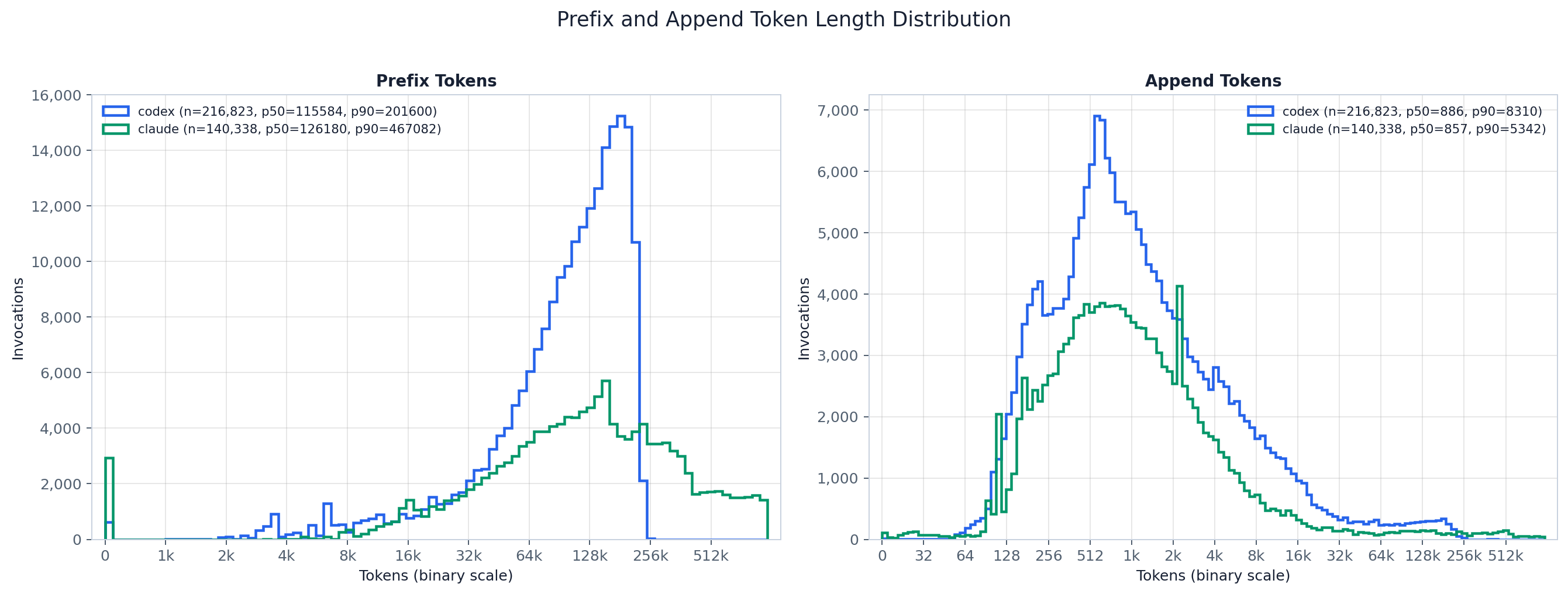
两张直方图大致相差两个数量级。前缀(缓存)曲线远远堆积在右侧——Claude 的中位步骤要重放约 126k 个缓存 token,Codex 约 116k——而追加曲线则居中在低百位区间(Claude 中位约 857 个 token,Codex 约 886 个),这才是一步会被重新计费的那一薄片。图例中的 p50/p90 量化了这一差距,且在所有步骤上都是精确的。要点正是编码智能体输入的核心事实:每一步压倒性地在重放累计上下文,而只为其上一层薄薄的新增量付费。
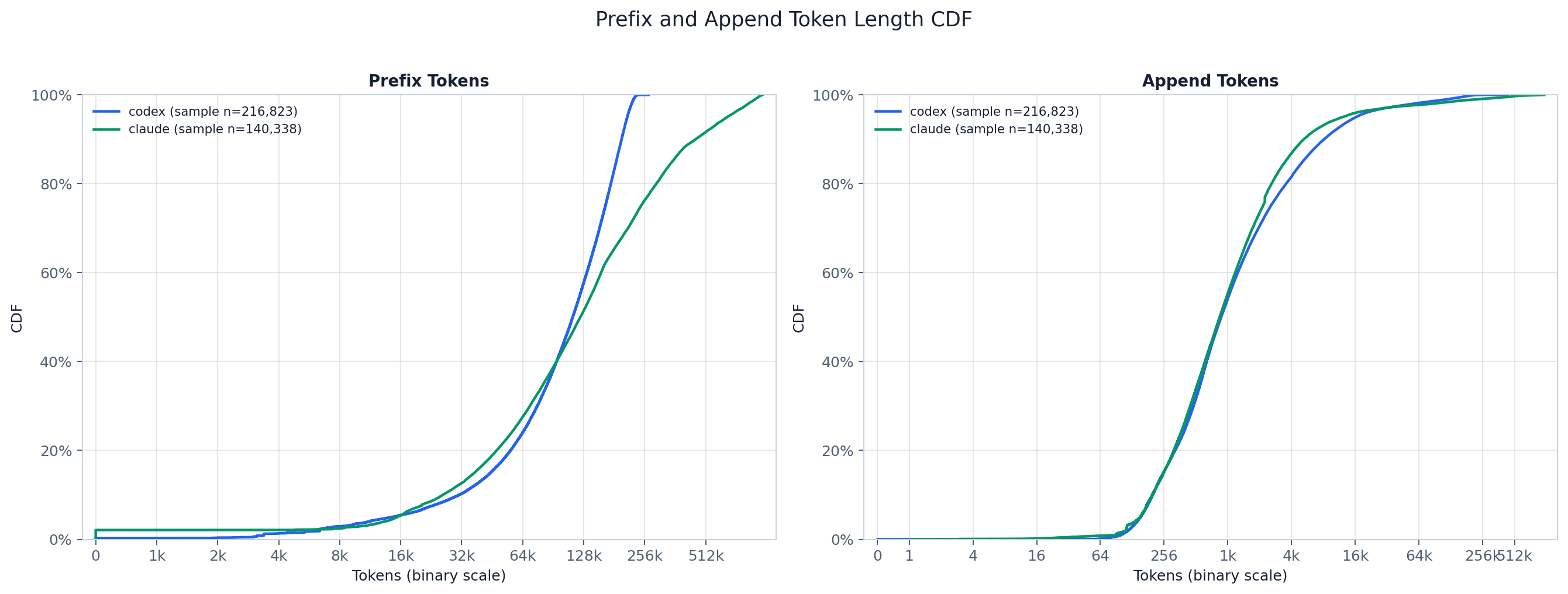
CDF 把这种分离显式化了。前缀曲线起升较晚,并一路爬升到几十万的区间——Claude 更长的上下文窗口把它的前缀尾部拉伸到接近 918k token 的 p99,而 Codex 在接近 231k 处就饱和——而追加曲线则早早饱和,因为大多数追加都很小。看每条曲线在 50%/90% 处的横切位置,就能比较一个提供商的典型输入成本与它的尾部,并注意两个提供商主要在前缀尾部分化,而非追加主体。
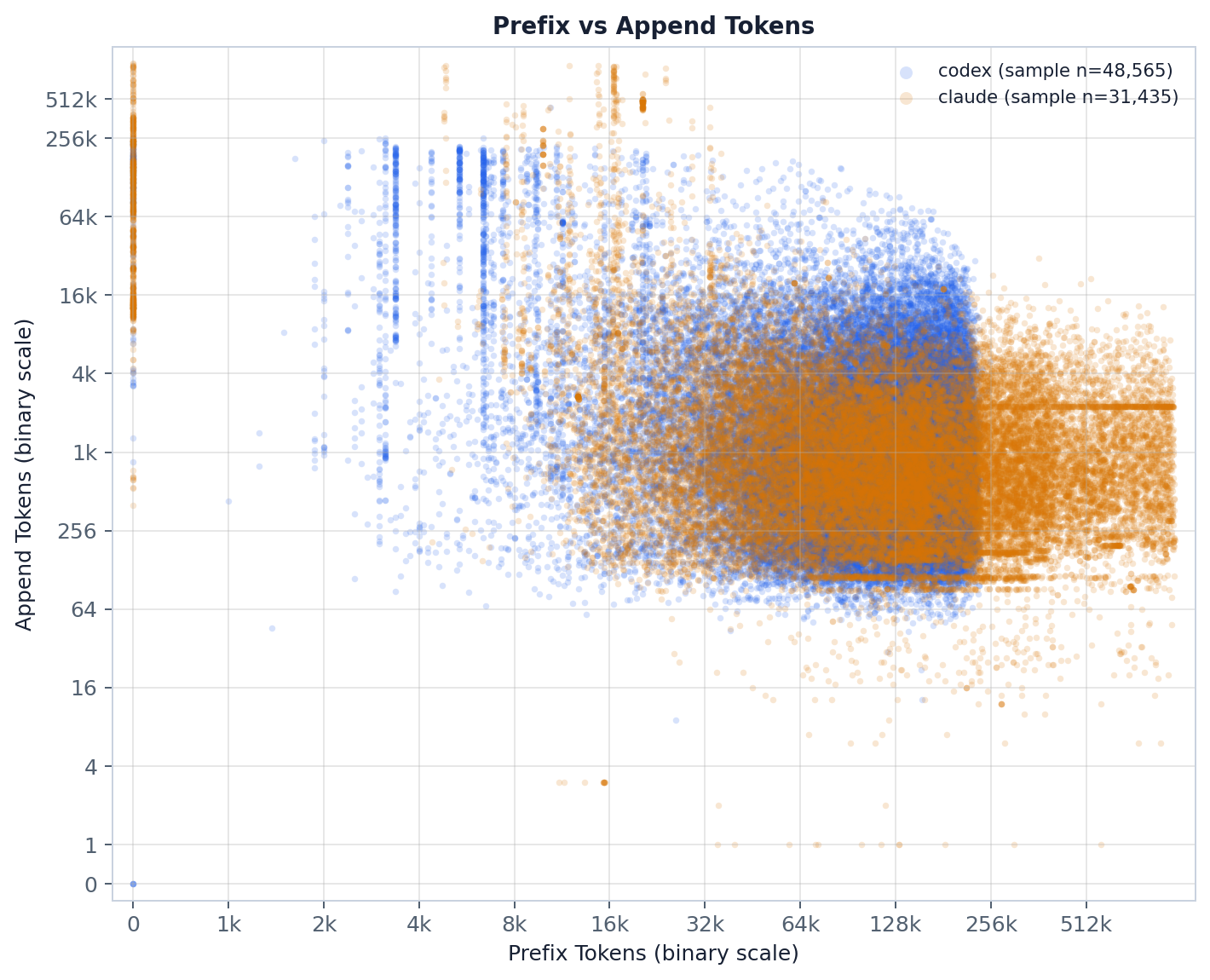
散点图揭示了两个边缘分布背后的联合结构(即论文的 fig:prefill_append_relationship)。大多数步骤聚集在前缀为 32k–128k、追加为 256–8k 处,但有两种区制(regime)分离出来。一个小前缀组(约 16k 以下)携带相对大的追加——这些是前缀缓存未命中以及冷的初始预填充,此时几乎没有内容被缓存,所以大部分 prompt 都作为新内容付费。大前缀组只追加很少——即普通的会话内增长,一步只是把一个工具结果或用户轮次叠加到已经缓存的上下文之上。所以一个大的复用前缀并不意味着一个大的追加;两者实际上是此消彼长的权衡。这是一个确定性的视觉子采样(至多 --pair-sample-size 个点),因此读它是看形状而非精确密度——定量解读请用 CSV/CDF。
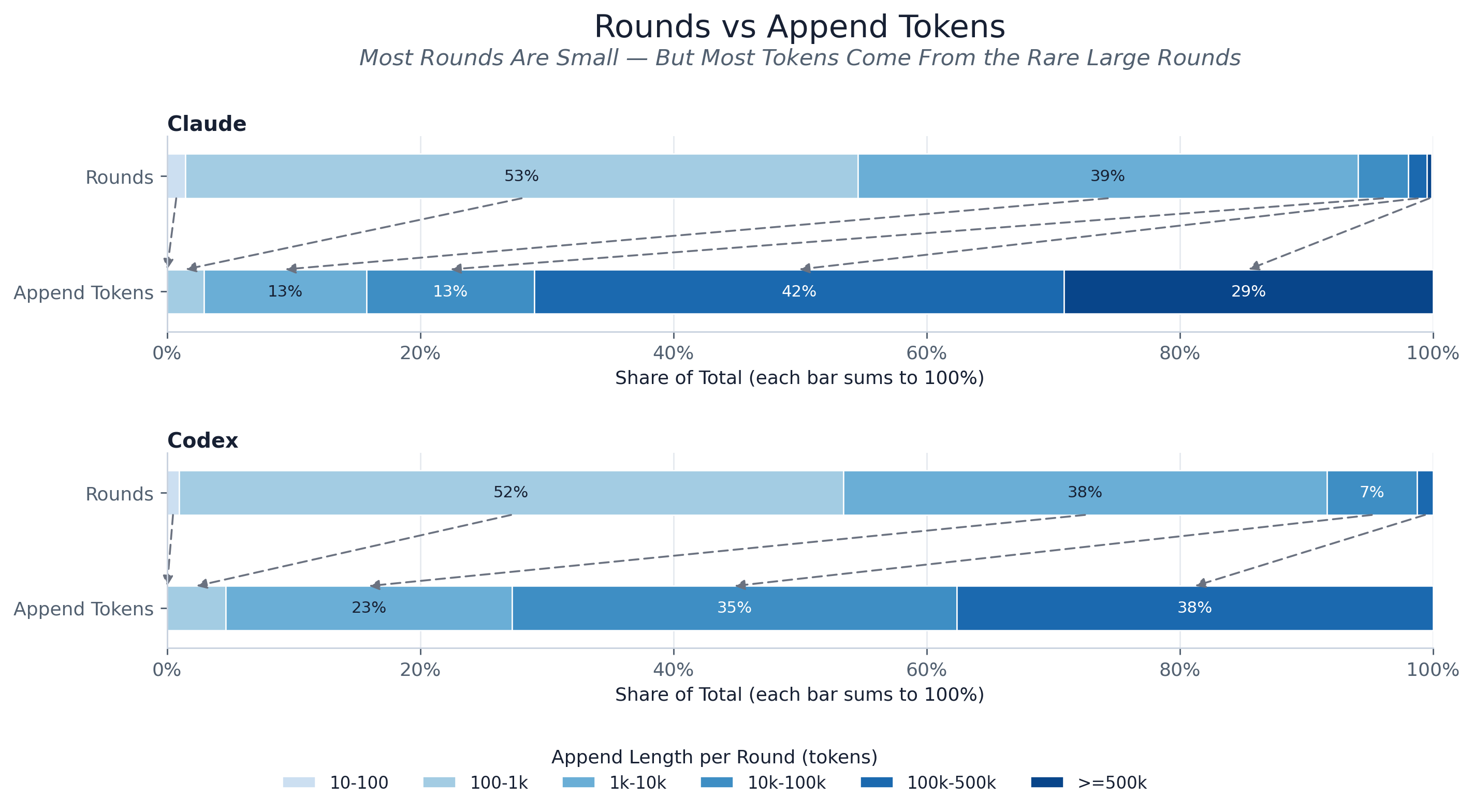
每个提供商两根堆叠柱——上为步骤占比,下为追加 token 质量占比——基于相同的追加长度桶(即论文的 fig:prefill_weighted_bar)。两根柱互相倒置:超过 90% 的步骤追加少于 1k token,但全部被追加的 token 中超过 70% 来自那些罕见的、追加 10k 或更多的步骤。从计数柱指向质量柱的箭头点明了这一点——尽管按计数几乎每一步都很小,预填充工作负载却由一小撮大追加步骤的尾部主导。新 token 的开销,以及缓存未命中的成本,正是集中在那条尾部。
trace 中的每个智能体步骤都带有一份输入 token 的核算:
input_tokens_total = prefix_tokens + newly_append_tokens。
cache_read_input_tokens;Codex 为 cached_input_tokens)。input_tokens + cache_creation_input_tokens;Codex 为 input_tokens_total − cached_input_tokens)。
完整的缓存核算推导见 ../../../docs/prompt_cache_accounting.md。本实验渲染前缀/追加分布(直方图 + CDF)、一张前缀-vs-追加散点图,以及一个按 token 质量加权的追加长度视图。
方法与假设:
sampled 列恒为 False,且 sample_count 等于完整的 count。)分位数使用 np.percentile(线性插值);均值通过按 ingest(round_pk)顺序对每组数值求和,精确复现旧的滚动浮点求和。>= 0 时才计入(旧 NumericTracker 的 allow_zero 规则);null 计入 missing,负值计入 invalid。追加加权分箱与散点图使用前缀与追加都 >= 0 的行(旧 loader 的成对门槛)。--group-by(默认 provider;也可 model / provider_model),并带有 <unknown-provider> / <unknown-model> 的 COALESCE 回退,镜像旧的 group_key。--pair-sample-size,默认 80k)。子采样不再用旧的 reservoir,而是在 SQL 中按代理键(surrogate key)的 Knuth 乘法哈希选取:在 prefix_tokens >= 0 AND newly_append_tokens >= 0 的行上执行 ORDER BY (round_pk * 2654435761) % 1000000, round_pk LIMIT <pair-sample-size>。这在不同 DB 构建与不同引擎间都可复现,但它不是旧的 reservoir,因此散点图与迁移前的运行并非逐字节兼容(CSV 是兼容的)。plot.py 是一条建立在共享 trace DuckDB 之上的 query→shape→plot 流水线:
load_token_groups(con, *, group_by)——按组返回前缀/追加的 MetricStats(按 ingest 顺序的每一个有效值,加上 missing/invalid 计数)以及该组的总 rows,外加一个 all 组。MetricStats.summary() 精确推导 count/mean/min/max/percentiles。scatter_pairs(con, *, group_by, sample_size)——上文描述的确定性 (group, prefix, append) 视觉子采样。append_bins(con, *, by_provider)——全局及按提供商的追加 token 加权分箱(每个半开桶的步骤数 + 累加追加 token),在成对门槛过滤后的行上精确计算。plot_token_histograms / plot_token_cdfs / plot_prefix_append_scatter /
plot_append_weighted_bins——各张图(matplotlib 行为与迁移前脚本一致)。write_token_summary / write_append_weighted_bins——两份 CSV。main()——接入标准的 trace_db CLI(--db | -i/--input | -o/--output-dir),并嵌入自包含的 PNG sidecar。数据层(解析、代理键、schema)位于 artifacts/utils/trace_db.py;参见 artifacts/utils/DB_SCHEMA.md。
# default merged trace, output next to this README
uv run python artifacts/llm_generation/prefix_append_distribution/plot.py
# a specific trace (materialized to a temp DuckDB cache on first use)
uv run python artifacts/llm_generation/prefix_append_distribution/plot.py -i trace/sample.jsonl
# a prebuilt DB (run_all.py's build-db step passes this), into a chosen dir
uv run python artifacts/llm_generation/prefix_append_distribution/plot.py --db /tmp/trace.duckdb -o /tmp/out
有用的 flag:--group-by(provider / model / provider_model)、--max-groups(最多绘制的组数,默认 8)、--pair-sample-size(散点子采样,默认 80000)。
prefix_append_distribution.png——前缀 vs 追加 token 的直方图。prefix_append_cdf.png——前缀 / 追加 token 长度的 CDF。prefix_vs_append_sample.png——前缀-vs-追加散点图(确定性视觉子采样)。append_tokens_weighted_bins.png / .csv——按 token 质量加权的追加分箱。token_length_summary.csv——按组的前缀/追加分位数、均值、min/max 及计数。这些 PNG 是自包含的——它们内嵌了本 README、各 CSV 以及绘图代码
(plot.py + 共享的 artifacts/utils/ 模块)。用
python artifacts/utils/png_sidecar.py extract <png> 解包。