
缓存前缀、调整后追加与输出 token 的完整分布并排放在一起、在同一共享 token 轴上画成半透明的”纺锤(spindle,类似 violin)“形状时,是什么样子?
缓存前缀、调整后追加与输出 token 的完整分布并排放在一起、在同一共享 token 轴上画成半透明的”纺锤(spindle,类似 violin)“形状时,是什么样子?
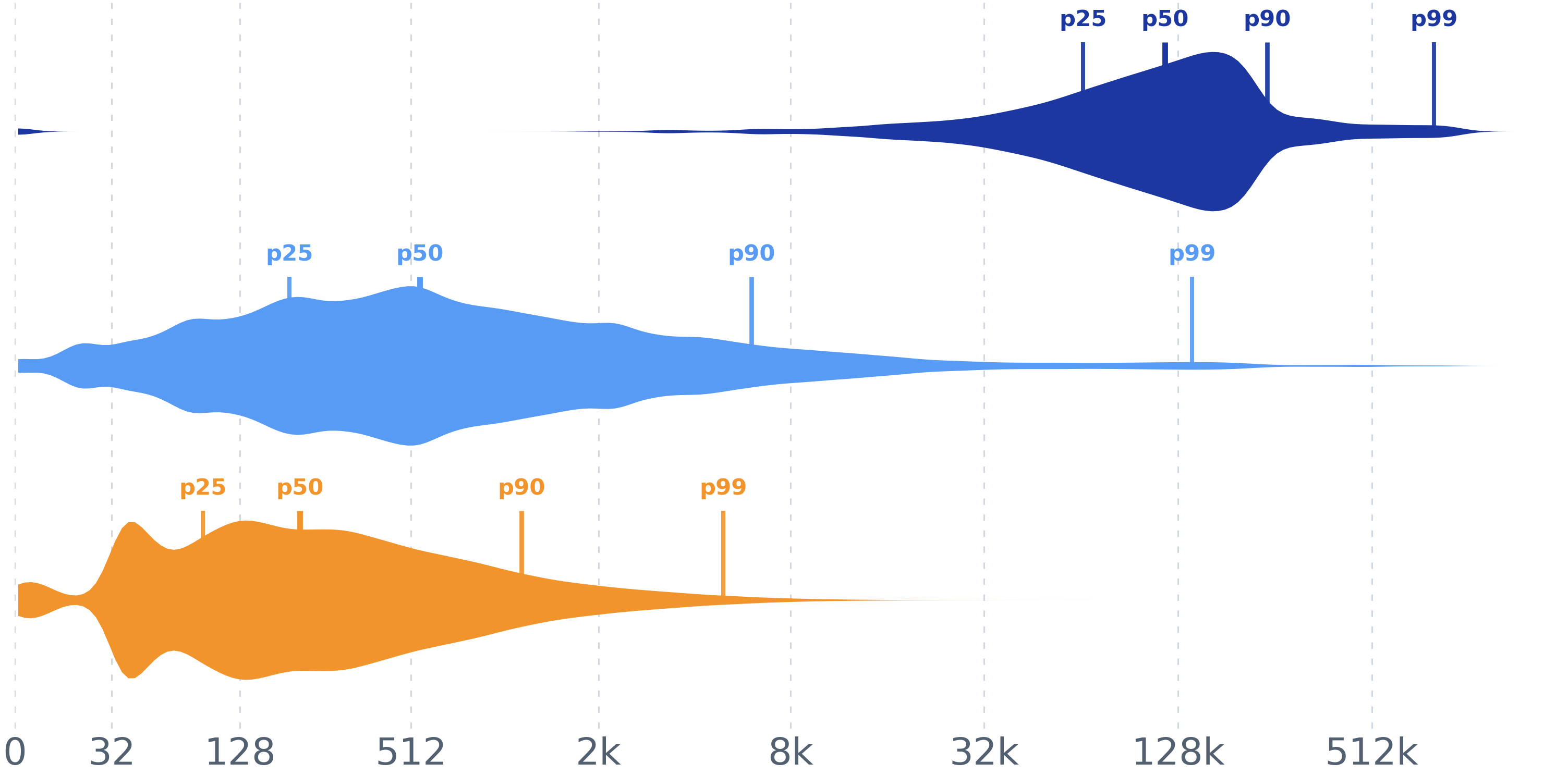
trace 中的每一行是一个智能体步骤。本实验把三个单步 token 量折叠成单一压缩 token 轴上的三个堆叠纺锤,以便一眼比较它们的典型大小与尾部。
方法与假设:
prefix_tokens(输入中的缓存 / 缓存读取部分)。newly_append_tokens − prior-step output,仅在上一个步骤是 Claude 或 Codex gpt-5.5(即上一次输出会被回送进下一次输入的那些提供商)时才应用。用于减法的 Codex 输出代理(output proxy)是 visible 输出(output_tokens − reasoning_output_tokens);结果在 0 处截断。对仅在**同一会话内的相邻步骤(adjacent steps in the same session)**之间形成(round_index 恰好相差 1)。output_tokens——它不配对、也不调整,因此它的纺锤覆盖所有步骤,而非仅配对的那些。session_id 分组,并在会话内以 round_index 排序、以摄入序号作为并列时的 tie-break(ORDER BY round_index, ingest_seq)——复现旧版在行序 JSONL 上的稳定排序。纺锤统计量(直方图密度、分位数、min/max)与顺序无关,因此无论会话迭代顺序如何,逐 CSV 的输出都逐字节一致。log2(tokens + 32) − log2(32),使得稠密的 0–32 token 区域不会在视觉上被过度拉伸。分位数在全量数据上使用线性插值(不抽样)。这是一个**混合(hybrid)**实验:trace DuckDB 负责单遍摄入,Python 保留配对启发式、纺锤密度/分位数计算以及绘图。
load_pairs(con) — 一条查询以会话/step 顺序拉取 step 标量(session_id, provider, model, round_index, prefix_tokens, newly_append_tokens, output_tokens, reasoning_output_tokens);Python 按会话分组、形成相邻对、应用减法策略(should_subtract_previous_output、output_proxy),并收集未配对的输出 token 序列。这是唯一的数据加载代码;其下的一切与迁移到 DuckDB 之前的版本保持不变。percentile(...) / summary_row(...) — 精确的线性插值分位数以及各指标的汇总记录。token_axis_x(...) / token_ticks(...) / smooth_density(...) — 压缩 token 轴,以及为每个纺锤赋予其形状的高斯平滑直方图。plot_combined_spindles(...) — 带 p25/p50/p90/p99 标记的三个堆叠半透明纺锤;write_summary(...) — 各指标的分位数 CSV。数据层位于 artifacts/utils/trace_db.py(参见 artifacts/utils/DB_SCHEMA.md)。
# default merged trace (materialized to a temp DuckDB cache on first use)
uv run python artifacts/llm_generation/token_spindles/plot.py
# a specific trace
uv run python artifacts/llm_generation/token_spindles/plot.py -i trace/sample.jsonl
# a prebuilt DB (run_all.py's build-db step passes this), into a chosen dir
uv run python artifacts/llm_generation/token_spindles/plot.py --db /tmp/trace.duckdb -o /tmp/out
--db | -i/--input | -o/--output-dir 是标准 I/O flag;-o 默认为本文件夹。
token_spindles_transparent.png — 组合后的半透明纺锤图。token_spindle_summary.csv — 各指标的计数(positive / zero)与分位数(p25, median, p90, p95, p99, min, max)。result_analysis.md — 生成的运行日志(策略说明、轴说明、配对统计)。每张 PNG 都嵌入了本 README、汇总 CSV,以及 plot.py。可用 python artifacts/utils/png_sidecar.py extract <png> 解包。