
每个智能体步骤的输入中,有多大比例是由缓存的前缀提供的?这个前缀命中率在用户触发的步骤 与工具触发的步骤之间又是如何分布的?
每个智能体步骤的输入中,有多大比例是由缓存的前缀提供的?这个前缀命中率在用户触发的步骤 与工具触发的步骤之间又是如何分布的?
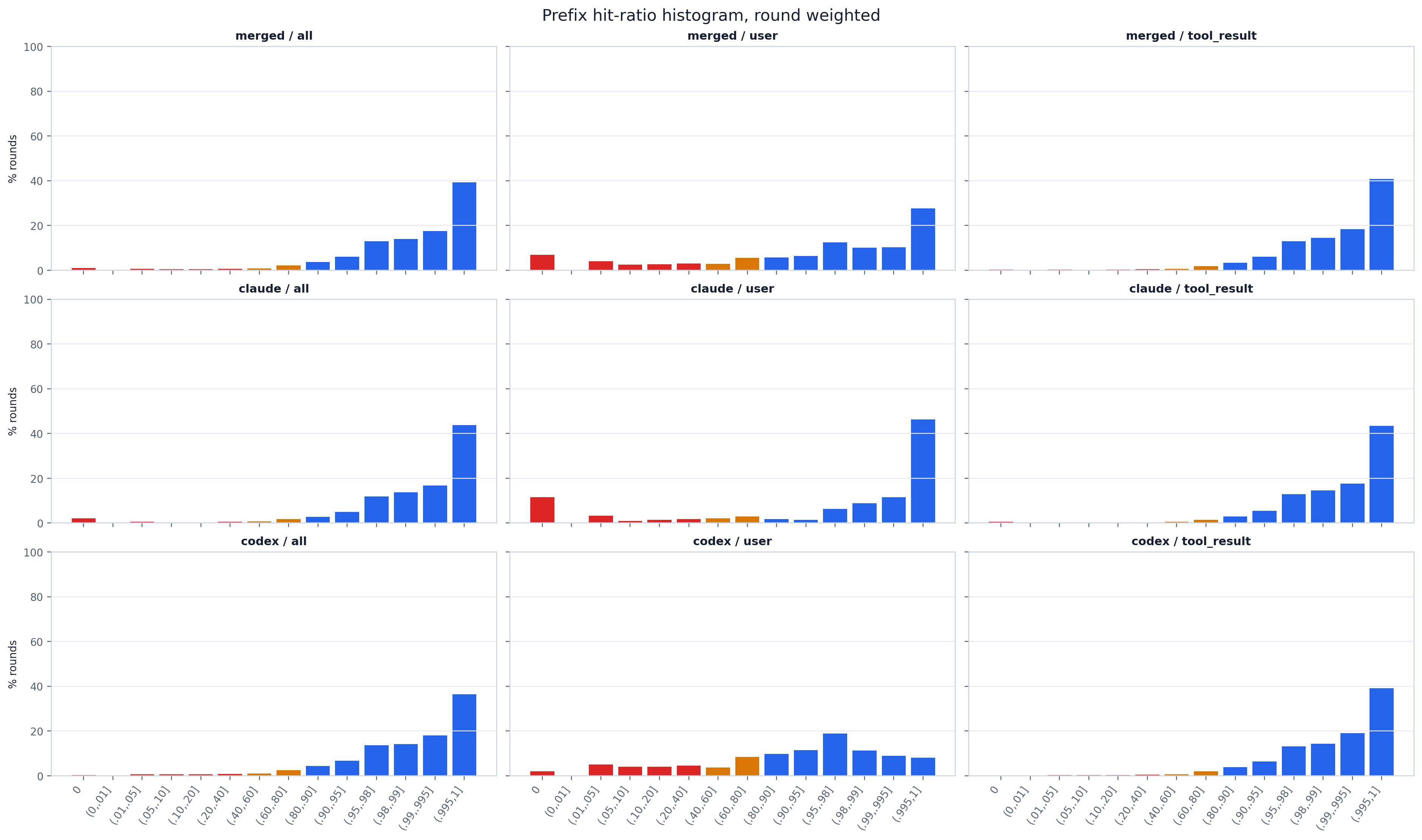
一个 scope × trigger 的按步骤加权命中率直方图网格(柱形按命中率区间用红/琥珀/蓝着色)。最主要的信号
是顶端 (.99,.995]/(.995,1] 分箱处的一根高柱:绝大多数步骤都是近乎完美的缓存命中,因此编码智能体
每个步骤只需为新追加的薄薄一片付费。按触发来源的拆分正是 tab:prefix_cache_hit_rate 的核心结论:
由 tool_result 发起的步骤紧紧聚集在高端(按 token 加权约 97.5% 命中,先前上下文几乎逐字续接),
而由 user 发起的步骤则带有一条明显的低命中率尾巴(约 84% 命中)—— 在长时间的人类停顿后到来的新用户
消息会使更多的前缀失效。将各提供商行与 merged 行对比,可以看出是否由某一个提供商主导了这条尾巴。
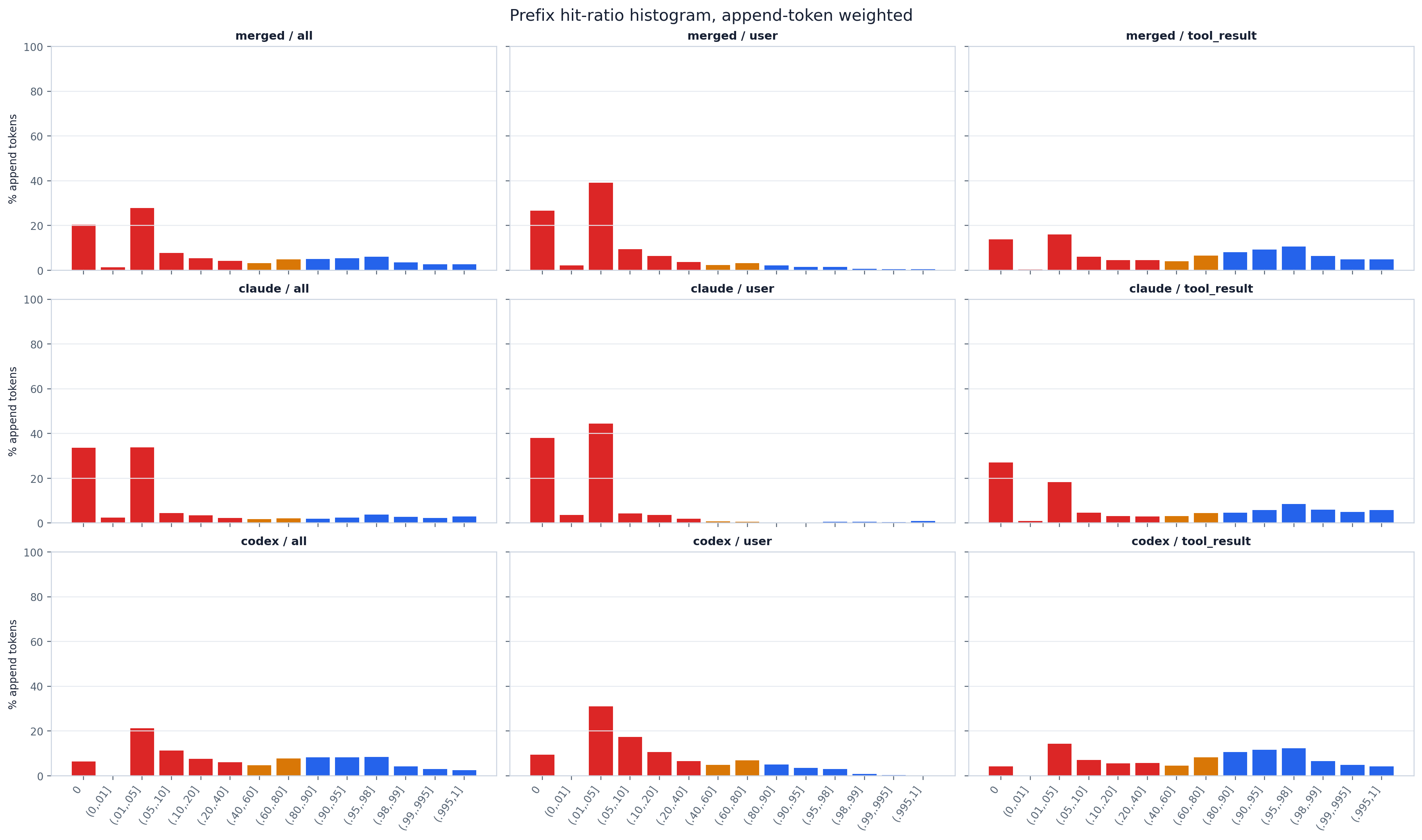
同样的面板,但每个步骤按其追加 token 数加权,因此柱形展示的是token 质量(也即可计费成本)实际落在
何处,而非步骤计数落在何处。其形态相比按步骤加权的视图发生了显著变化:高命中分箱收缩,低命中分箱增长,
因为那些稀少的低命中步骤恰恰是追加了大量新文本的步骤。读这一面板可以找出新 token 开销集中在哪里 ——
cache_hit_ratio_summary.csv 的 append_hit_* 列给出了每个区间精确的质量占比。
| Metric | Claude | Codex | Total |
|---|---|---|---|
| Prefix cache-hit rate | 95.8% | 95.7% | 95.7% |
| Prefix hit rate (user-initiated) | 86.9% | 78.2% | 84.4% |
| Prefix hit rate (tool-result) | 97.9% | 97.2% | 97.5% |
按步骤类型划分的按 token 加权命中率(论文的 tab:prefix_cache_hit_rate)。整体来看缓存命中率一致地高:
两个提供商都将约 96% 的 prompt token 由前缀缓存提供(Claude 95.8%,Codex 95.7%)。有趣的拆分在于
触发来源 —— 用户触发的步骤命中率要低得多(Claude 86.9%,Codex 78.2%),因为人类的思考时间会把空闲间隔
拉长到超过驱逐窗口,而 工具触发步骤则保持近乎完美(97.9% / 97.2%),因为它们几乎立即续接。
因此残留的未命中集中在智能体等待人类、而非等待工具的地方。
轨迹中的每个智能体步骤都携带一份输入 token 的账目
(input_tokens_total = prefix_tokens + newly_append_tokens)。本实验将缓存的前缀视为缓存命中,
将新追加的 token 视为未命中,并报告每个步骤的命中率,按触发该步骤的来源进行拆分。
方法与假设:
prefix_tokens / (prefix_tokens + newly_append_tokens) —— 即
输入 token 中属于缓存读取而非新计费的那一部分占比。sum(prefix_tokens) / sum(prefix_tokens + newly_append_tokens)。
论文表格中,整体那一行使用所有有效步骤,而触发来源各行则使用首事件为 user_message /
tool_result 的步骤。timing_events 中 event_index = 1,即按顺序的第一个事件)是 user_message 或
tool_result 时,该步骤才会被纳入;所有其他首事件类型(以及没有时序事件的步骤)都会被剔除。
该首事件同时决定触发来源:user_message 对应 user,其余为 tool_result。first_input_event_type
这一列不会被使用 —— 它与首个时序事件存在分歧(当存在首个时序事件时它仍可能为 null),
因此遗留的 timing_events[0] 语义是通过时序事件表来复现的。prefix_tokens 与 newly_append_tokens 都必须非空,且二者之和必须
> 0(零值/空步骤不贡献任何内容,也绝不会出现除以零)。np.percentile 一致)、直方图和分箱都通过共享的
轨迹 DuckDB 在每一个入选步骤上计算 —— 不存在蓄水池采样上限。merged 范围,并同时归入其自身的触发来源和
all 触发来源。报告的范围有:merged / claude / codex(提供商为 null 时回退为
unknown)。按追加加权的视图会用每个步骤的追加 token 数对其加权,以展示 token 质量
集中在何处,而不仅仅是步骤的计数。analyze.py 是一条在共享轨迹 DuckDB 之上的 query→shape→write/plot 流水线:
read_groups(con) —— 将 rounds 与首个时序事件
(timing_events WHERE event_index = 1)做一次 join,经门槛筛选并按 round_pk(文件顺序)排序,
返回 {(scope, trigger): HitRatioGroup},其中每个分组保留每个步骤的 (hit_ratio, append_tokens)。缓存命中的定义、入选门槛以及提供商/merged 的扇出逻辑都位于此处。percentile(...) / hit_bin_index(...) / bin_color(...) —— 精确的分位数插值,以及 CSV 和图表
共享的固定命中率分箱边界/颜色。write_summary_csv / write_bins_csv / write_round_split_csv —— 三个 CSV。plot_histograms(..., weighted_by_append=...) —— SCOPES × TRIGGERS 的面板网格,分别按步骤加权
和按追加 token 加权各渲染一次(matplotlib 行为与迁移前脚本保持不变)。main() —— 将标准的 trace_db CLI(--db | -i/--input | -o/--output-dir)接入上述逻辑,
并嵌入自包含的 PNG sidecar。数据层(解析、代理键、schema)位于 artifacts/utils/trace_db.py;参见
artifacts/utils/DB_SCHEMA.md。
# default merged trace, output next to this README
uv run python artifacts/prefix_cache/cache_hit_ratio/analyze.py
# a specific trace (materialized to a temp DuckDB cache on first use)
uv run python artifacts/prefix_cache/cache_hit_ratio/analyze.py -i trace/sample.jsonl
# a prebuilt DB (run_all.py's build-db step passes this), into a chosen dir
uv run python artifacts/prefix_cache/cache_hit_ratio/analyze.py --db /tmp/trace.duckdb -o /tmp/out
# CSV-only (skip figures)
uv run python artifacts/prefix_cache/cache_hit_ratio/analyze.py --no-plots
cache_hit_ratio_histogram.png —— 按步骤加权的命中率直方图,按范围 × 触发来源分面板。cache_hit_ratio_append_weighted_histogram.png —— 同样的面板,但按追加 token 加权。cache_hit_ratio_summary.csv —— 每个 (scope, trigger):步骤/追加计数、均值、分位数
(p01…p99),以及步骤占比 / 追加占比的各阈值(<0.5、0.5–0.9、>=0.9/0.95/0.98/0.99)。cache_hit_ratio_bins.csv —— 每个 (scope, trigger, bin):在固定命中率分箱上的步骤计数 + 占比
与追加 token 计数 + 占比。cache_hit_ratio_round_split.csv —— 每个 (scope, trigger):在粗粒度
<10% / 10-40% / 40-80% / 80%+ 桶上的步骤计数/占比。cache_hit_ratio_token_weighted.csv —— 供论文表格使用的按 token 加权命中率输入。prefix_cache_hit_rate_table.tex —— 供论文使用的 LaTeX 表格主体。cache_hit_ratio_table.md —— 该表格的 GFM Markdown 镜像,渲染在网页详情页上。这些 PNG 是自包含的 —— 它们内嵌了本 README、各 CSV 以及绘图代码(analyze.py
加上共享的 artifacts/utils/ 模块)。用
python artifacts/utils/png_sidecar.py extract <png> 解包。