
随着前缀缓存的驱逐超时 tau 增大,可达到的缓存命中率会上升(更少的空闲间隔会超出 tau),
但你必须预留的 KV 存储也会上升(空闲请求会更久地持有其 KV)。本实验扫描 tau 并同时报告二者,揭示这一
权衡及其边际收益递减。
随着前缀缓存的驱逐超时 tau 增大,可达到的缓存命中率会上升(更少的空闲间隔会超出 tau),
但你必须预留的 KV 存储也会上升(空闲请求会更久地持有其 KV)。本实验扫描 tau 并同时报告二者,揭示这一
权衡及其边际收益递减。
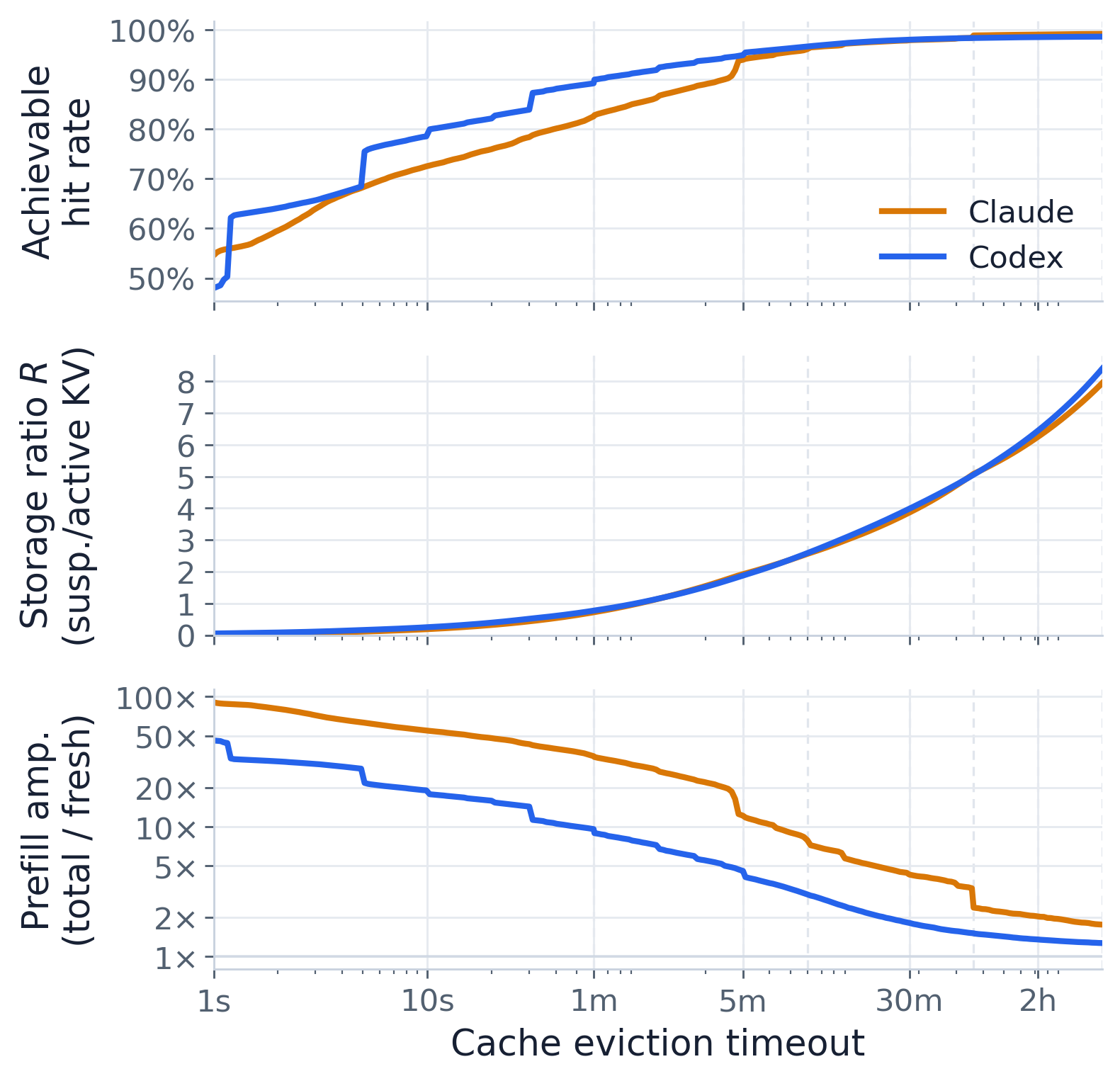
三个共享驱逐超时 x 轴的堆叠面板(论文的 fig:eviction_tradeoff):可达命中率、存储比 R,以及
预填充放大,每个都带有其无驱逐最优值作为点线参考。这一权衡先陡后平。对于 merged 轨迹,将超时从
1 min 提升到 1 h 使可达命中率从 85.4% -> 98.6%,但使存储比从 R = 0.74 -> 5.07 增长
(约 7x 的挂起 KV)。大部分收益很便宜:到 5 min 时命中率已达约 94%,此时 R ~ 1.9,而继续推进到 1 h 仅
多买到约 4 个百分点,却要付出约 2.7x 的存储。底部面板把这种浪费具象化:放大下限为 1x(无驱逐的
缓存只预填充新鲜),并随着驱逐收紧而膨胀 —— merged 在 1 min 时为 18.9x,5 min 时 7.4x,
1 h 时 1.8x。
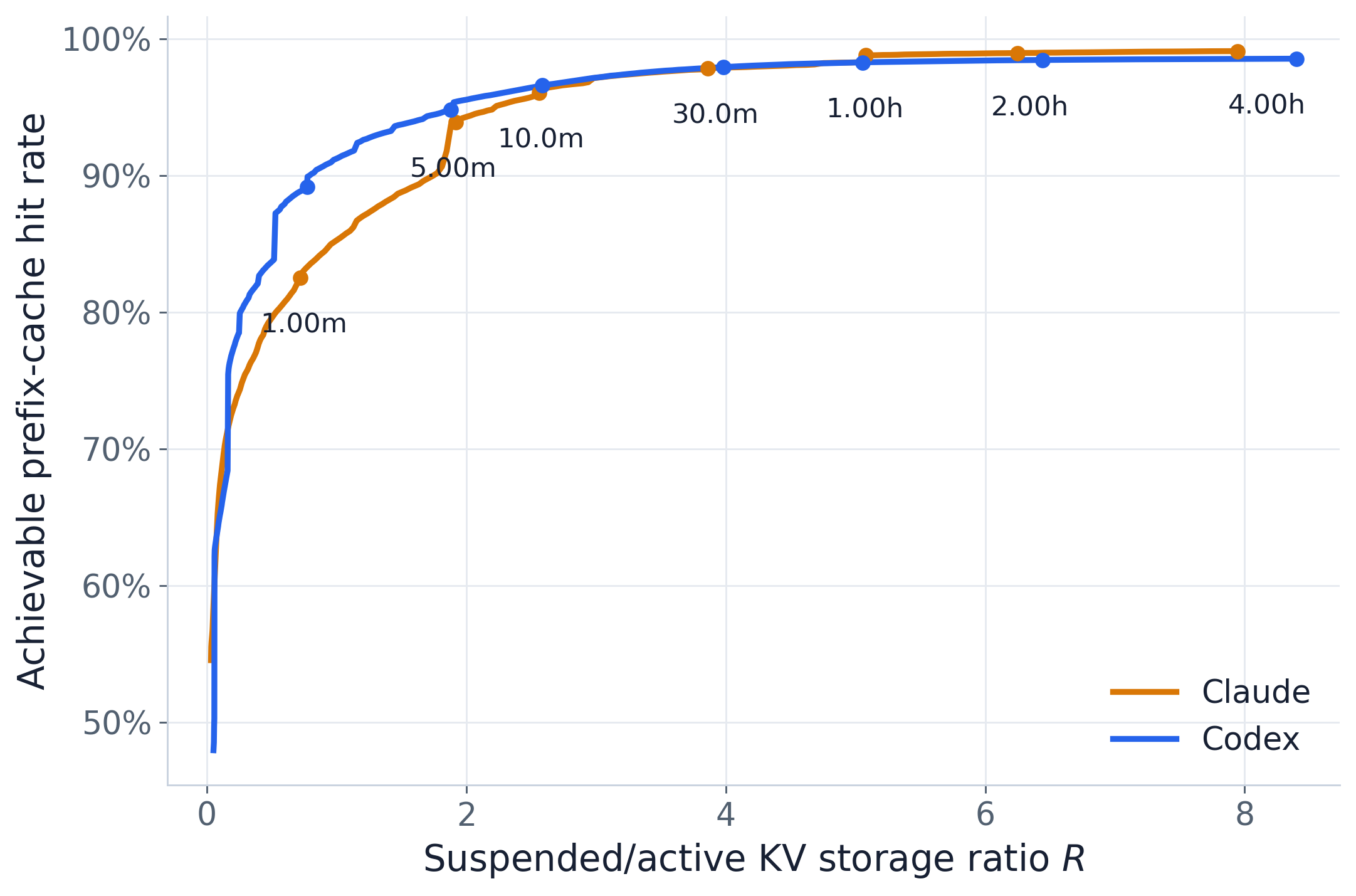
可达命中率对存储比 R,并标注驱逐时间的地标 —— 即把同一次扫描读作一条帕累托前沿。拐点位于约
5 min 附近:越过它,你将为不断缩水的命中率增益付出陡增的存储。实际部署的缓存作为参考点被叠加上去;它
预填充约新鲜最小值的 5.3x(Claude 8.1x,Codex 3.9x),恰好是 redundant_prefill 表格中的
1 / (fresh % of append)。该工作点落在理想化曲线上的有效驱逐时间约为 8 min处(Claude 约
10 min,Codex 约 5 min):实际的前缀缓存行为就像一个在约 8 分钟空闲后驱逐的理想缓存。因此
redundant_prefill 与本驱逐扫描所揭示的与最优状态之间的差距,是同一件事的两个视角。
一个理想化的、每个步骤二元的模型(论文的规则):如果一个步骤之前的空闲间隔 <= tau,其前缀就是
完全命中;如果间隔 > tau,则是完全未命中(重新预填充)。
对每个会话步骤 S,与其前驱 P 配对,S 之前的空闲间隔为 g(用户步骤为人类思考时间;
tool-result 步骤为工具延迟):
L = prefix_tokens + newly_append_tokens —— S 处的总 prompt token。fresh = clip(max(0, L - L_prev) - output_tokens(P), 0, append) —— 真正新的用户/工具 token
(上下文增长减去前一个步骤的输出;与 redundant_prefill 定义相同,且 output_tokens 按
trace_facts/overview_summary 已包含推理)。fresh 是缓存永远无法提供的不可压缩预填充。cacheable = L - fresh —— 一个完美的、无驱逐的缓存所能提供的可复用 token。这是一个理想化缓存,其唯一的不完美之处就是驱逐超时:一个被保留的步骤(间隔 <= tau)只预填充
其 fresh token,一个被驱逐的步骤则重新预填充其整个上下文 L。在所有被覆盖的步骤上有两个按
token 加权的量:
hit_rate(tau) = sum_{g<=tau} cacheable / sum L (-> 1 - fresh/L = optimal as tau->inf)
prefill(tau) = sum fresh + sum_{g>tau} cacheable (tokens prefilled at tau)
A(tau) = prefill(tau) / sum fresh (prefill amplification; floors at 1x)
redundant_ratio(tau)= 1 - 1 / A(tau) (equivalent share-of-prefill form)
预填充放大 A 是底部面板:实际预填充的 token 数是不可压缩的 fresh 最小值的多少倍。一个无
驱逐的完美缓存只预填充 fresh,所以 A 下限为 1x;更紧的驱逐会重新预填充被驱逐
的上下文,从而将其放大。
实际部署的缓存作为参考被叠加上去(它不是那个理想化模型):它预填充 append(放大为
sum append / sum fresh)并提供 prefix(命中为 sum prefix / sum L)。该工作点落在理想化曲线上的
有效驱逐时间处 —— 即理想化命中率等于实际命中率时的那个 tau。这就是本节如何与静态的
redundant_prefill 表格相互印证的(后者的 1 / (fresh % of append) 正是实际放大系数)。
存储轴(有上限)。 空闲是由驱逐时间封顶的:在 tau 流逝之前你无法知道一个间隔是否会超出它,
所以无论如何 KV 都会被持有到 tau。设 gen_r 为每个轮次的输入->最后输出跨度(活跃解码时间),
R(tau) = sum_i min(g_i, tau) / sum_r gen_r (suspended-KV / active-KV storage ratio)
kv_active_ratio(tau)= 1 / (1 + R(tau))
这个 R 是论文 §7.5 推导中经过修正的存储比(R = (T_human + T_tool) / T_generation):空闲时间远超
生成时间,因此挂起的 KV 占主导,而 R 在长超时下会增长到远高于 1。
方法与假设:
cache_hit_idle_relationship:用户步骤的间隔为 first_activity - previous_round.last_activity;tool-result 步骤的间隔为领头 tool-result 时长的最大值(请求在其
工具运行期间的整段空闲墙钟时间,这正是挂起其 KV 的因素 —— 注意这与 kv_cache_active_ratio 不同,
后者把每一次单独的 tool-call 延迟求和)。kv_cache_active_ratio 的 input->最后输出 定义。fresh)又有可测量的空闲间隔时才计入;会话首个步骤和
无间隔的步骤会被排除。命中率是在被覆盖的步骤上按 token 加权的,因此它是一个可达缓存估计值,而非观测到
的系统命中率。load_step_arrays(con) —— 会话遍历(复用 cache_hit_idle_relationship 的间隔逻辑,外加
output_tokens),产出每个范围的向量 (gap, cacheable, total) 以及求和后的 fresh。load_generation_total_seconds(con) —— 每个范围的总活跃解码秒数。sweep_scope(...) —— 在共享的 formatters 超时网格上做一次向量化扫描:按间隔排序的累积和以闭式给出
hit_rate / redundant_prefill 以及封顶的 R。plot_tradeoff_by_timeout(...) / plot_pareto(...) —— 两张图。uv run python artifacts/prefix_cache/eviction_tradeoff/analyze.py # default merged trace
uv run python artifacts/prefix_cache/eviction_tradeoff/analyze.py --db /tmp/trace.duckdb -o /tmp/out
uv run python artifacts/prefix_cache/eviction_tradeoff/analyze.py --no-plots # CSV only
eviction_tradeoff_by_scope.csv —— 每个 (scope, tau):可达命中率、预填充放大、冗余预填充比、
新鲜下限、最优命中率、最优放大、存储比 R,以及 KV 活跃比。eviction_tradeoff_by_timeout.{png,pdf} —— 三个共享驱逐超时 x 轴的堆叠面板:可达命中率、
存储比 R,以及预填充放大(每个都带有其无驱逐最优值作为点线参考)。eviction_tradeoff_pareto.{png,pdf} —— 可达命中率 vs 存储比 R,并标注驱逐时间的地标。