
在单个编码会话内部,上下文窗口是如何一个智能体步骤接一个智能体步骤增长的——用户的消息落在哪里,有多少是廉价的缓存前缀对比新追加的输入,智能体又在哪里压缩并重新开始?
在单个编码会话内部,上下文窗口是如何一个智能体步骤接一个智能体步骤增长的——用户的消息落在哪里,有多少是廉价的缓存前缀对比新追加的输入,智能体又在哪里压缩并重新开始?
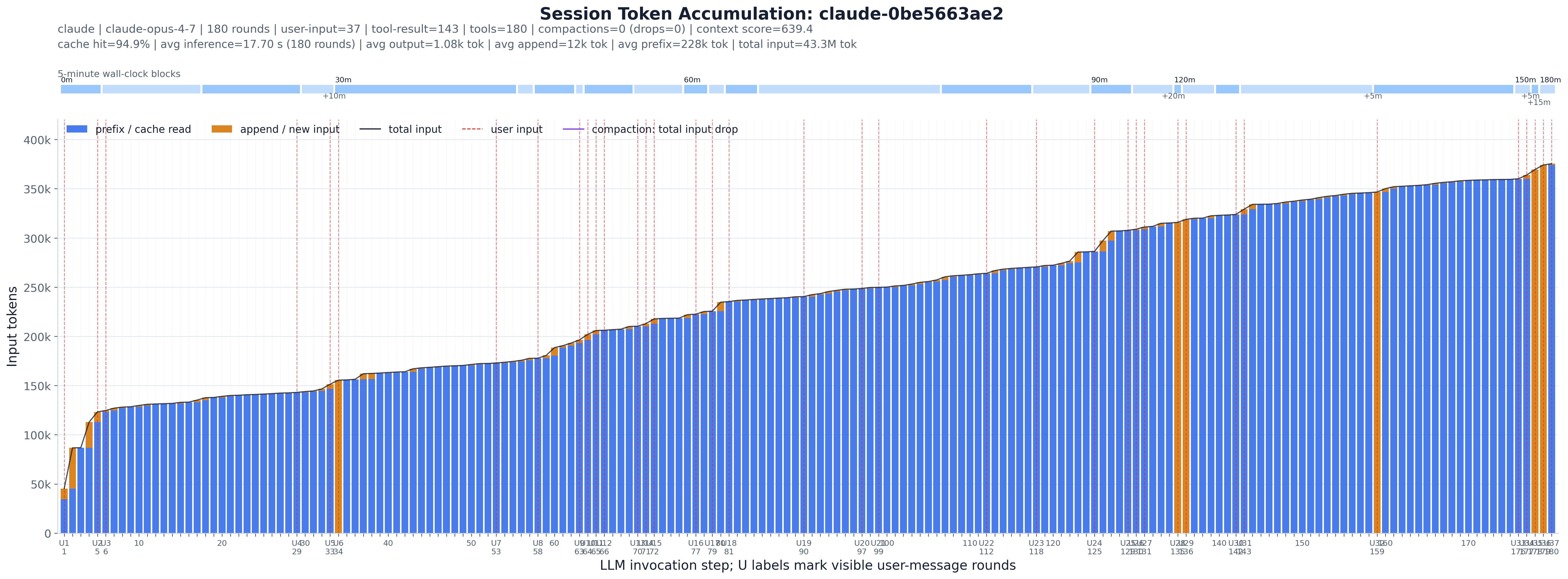
一个会话,被逐步骤观看(论文的 fig:session_progress_example;文件名只是该会话的哈希)。每张图的读法都相同:
C 标记是压缩——运行中的总量坍缩,会话重启它的上下文;这些条带显示它持续了多少步骤,以及它是压缩一次还是反复压缩。U 线是用户触发步骤;它们之间的宽阔间隔意味着在单条指令下长段的自主、由工具驱动的过程。trace 中的每一行是一个智能体步骤。本实验挑选少数几个有代表性的会话,对每一个,每个步骤画一根柱:缓存/前缀 token(蓝色)堆叠在新追加的输入 token(橙色)之下,并以一条折线在顶部表示运行中的总输入。一条细长的顶部条带把同样的这些步骤摆放在一条 5 分钟的墙钟时间线上,让你能看到智能体在哪里停顿。它是这套工具集里最接近于观看一个会话呼吸的东西。
方法与假设:
(round_index, first-event timestamp, ingestion order) 排序。ingestion-order 的 tie-break 即文件顺序,因此时间戳相等的步骤永远不会被重排。prefix_tokens / newly_append_tokens;它们之和是该次调用的完整输入大小。U1、U2、…)是那些其 timing event 包含一个可见 user_message 的步骤,也就是人类真正打字的地方——区别于工具触发步骤。--session-id 钉住特定会话。这是一个**混合式(hybrid)**实验:trace DuckDB 负责单遍 ingest,而 Python 负责那些不属于 SQL 的按会话启发式(排序、加窗、压缩检测、评分)。
load_sessions_from_db(con) —— 三条查询(步骤标量、每个步骤的 timing event、每个步骤的工具计数),全部按 ingestion 顺序,组装成 SessionStats 对象。这是唯一的数据加载代码;下面的一切都与迁移到 DuckDB 之前的版本相同。RoundRow / TimingEvent —— 一次调用及其 timing 行;first_observed_timestamp、
input_to_last_output_span_seconds、has_explicit_compaction_marker 推导出每个步骤的事实。find_compaction_markers(rounds) —— 带有 rebound 守卫的 显式 + 推断下降 逻辑。SessionStats —— 按会话的汇总以及三个选择评分。select_sessions(...) / select_window(...) —— 选哪些会话,以及(若有 --max-steps)选其中一个的哪一段连续窗口。plot_session(...) —— 堆叠柱 + 时间线图;write_outputs(...) —— 候选 CSV 以及所选会话的 JSON。数据层位于 artifacts/utils/trace_db.py(参见 artifacts/utils/DB_SCHEMA.md)。
# auto-select illustrative sessions from the default merged trace
uv run python artifacts/session/session_token_steps/plot.py
# a specific trace (materialized to a temp DuckDB cache on first use)
uv run python artifacts/session/session_token_steps/plot.py -i trace/sample.jsonl
# a prebuilt DB (run_all.py's build-db step passes this), into a chosen dir
uv run python artifacts/session/session_token_steps/plot.py --db /tmp/trace.duckdb -o /tmp/out
# pin exact sessions
uv run python artifacts/session/session_token_steps/plot.py --session-id <session_id>
选择旋钮:--top-sessions、--context-sessions、--compaction-sessions,以及
--min/--max-rounds 和 --min-user-input-rounds / --min-tool-result-rounds 过滤器、
--max-steps(给一个长会话加窗)、--candidate-limit(CSV 深度)。--select-offset /
--select-stride 把所选集合分片,用于并行渲染。
<session>_token_steps.png —— 每个所选会话一张图(文件名是会话 id 的稳定哈希)。session_token_steps_candidates.csv —— 每一个排名候选会话及其汇总和评分;selected 列标记哪些被绘制了。selected_session_token_steps.json —— 精确的选择结果及每个窗口的指标。每张 PNG 都嵌入了本 README、候选 CSV 以及 plot.py。可用
python artifacts/utils/png_sidecar.py extract <png> 解包。