
当工具被折叠为少数几个粗粒度类别(execute、file write/edit、file read/search、agent/task、web/lookup、…)时,调用和延迟在这些类别间是如何分布的 ——以及延迟长尾在少数慢调用中有多集中?
当工具被折叠为少数几个粗粒度类别(execute、file write/edit、file read/search、agent/task、web/lookup、…)时,调用和延迟在这些类别间是如何分布的 ——以及延迟长尾在少数慢调用中有多集中?
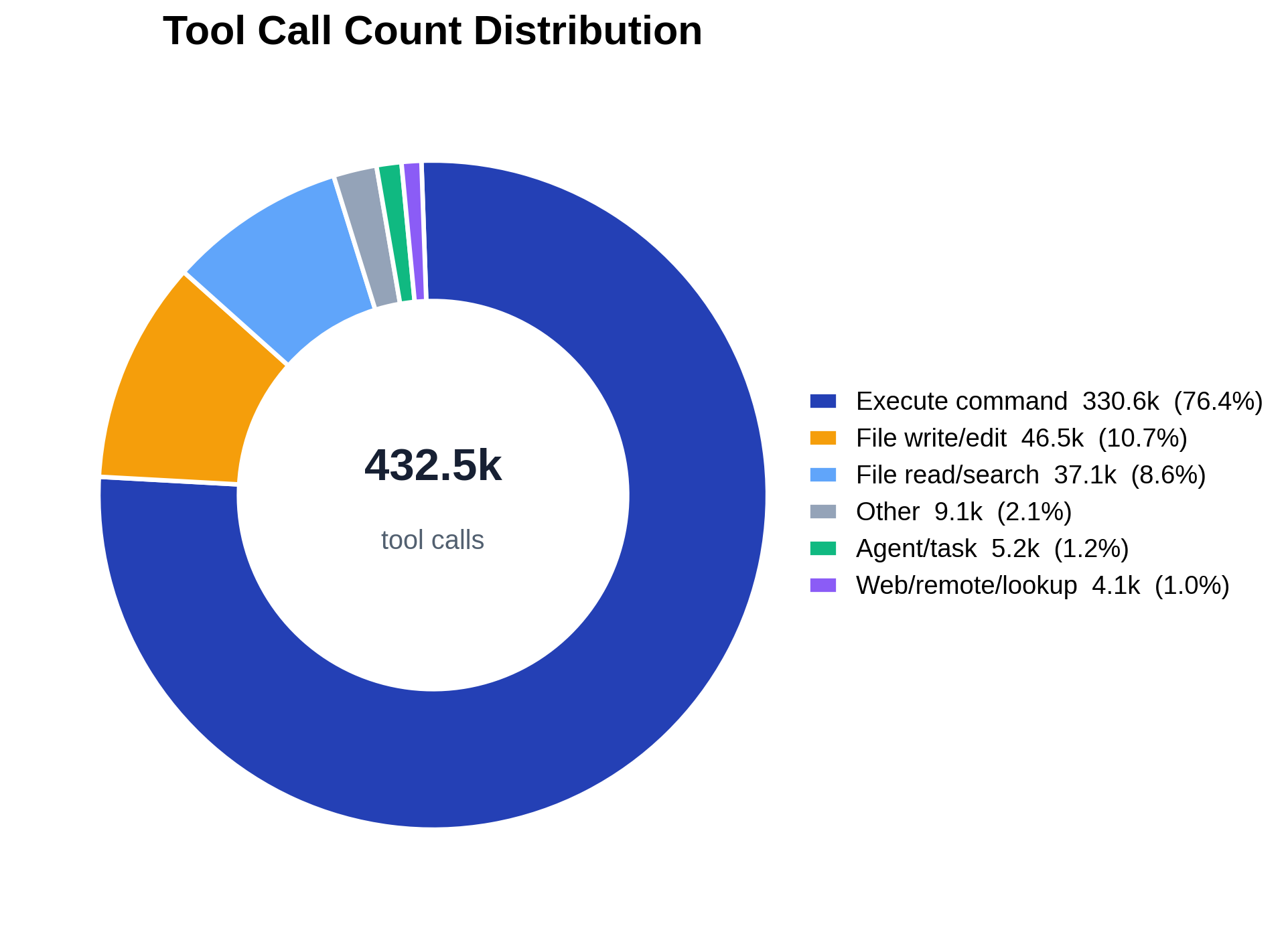
圆环图展示了智能体的工具调用如何在六个粗粒度类别间分布,且其排序
明显头重。仅 execute-command 就占全部调用的约 76%,file write/edit 约 11%、file
read/search 约 9%;agent/task(约 1.2%)和 web/remote/lookup(约 1.0%)是细薄的切片,
其余一切都被折叠进 Other(约 2.1%)。因此一旦把提供商特定的工具名归一化为共享
类别,智能体的工作就压倒性地是 shell 执行加文件 I/O。中心标签是
总调用计数,每个切片都标注其占比;图例带有精确计数,以使
小切片保持可读。
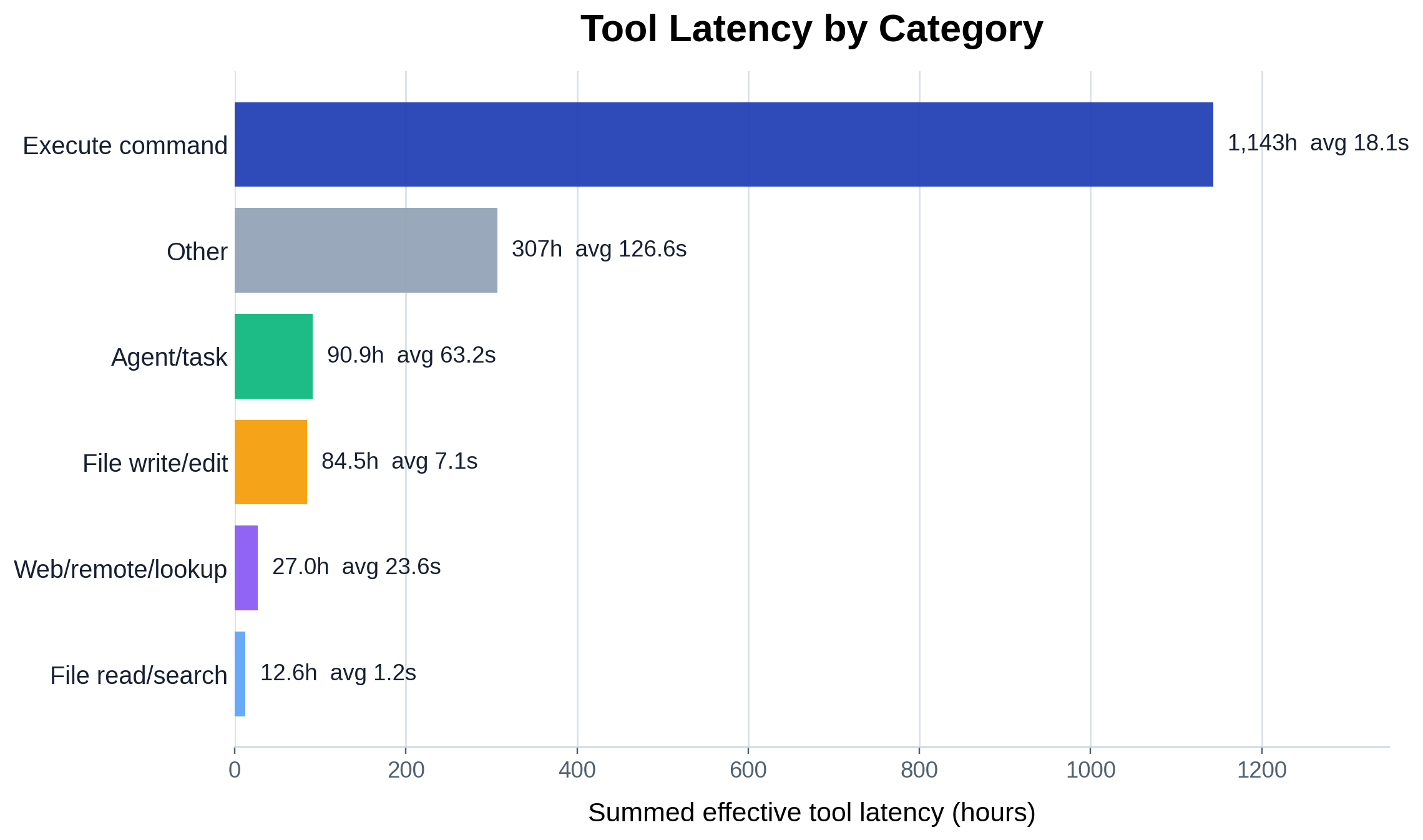
按有效延迟求和(小时)对相同类别重新排名,讲出了与计数环不同的
故事,因为逐调用成本相差超过两个数量级(每根柱都
标注了平均每次调用秒数)。Execute-command 仍以约 1143h 领先,但其约 18s
的平均逐调用成本被 agent/task(约 63s 平均,90.9h 总计)和 web/remote/lookup(约 24s 平均,
27.0h)远远盖过,而 Other 桶以约 307h(约 127s 平均)的表现远超其 2% 的调用
占比。File read/search 尽管是被调用第三多的类别,却仅以约 1.2s 每次调用花费约 12.6h。
这就是计数-vs-成本的差距:廉价的高频原语对比昂贵、更罕见、
会阻塞在真实工作或用户上的调用。
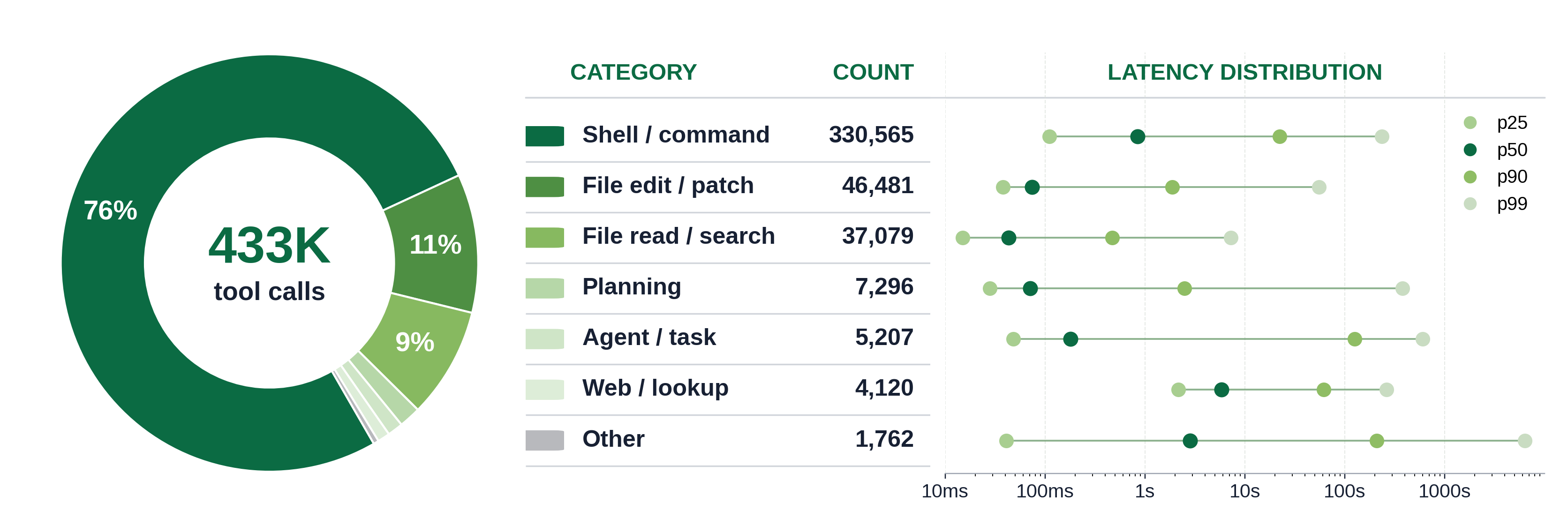
展示 dashboard 组合了 7 桶映射(额外拆分出
Planning)的三个视图:调用计数圆环图(左)、排名类别表(中),以及对数刻度的
延迟分位条(右,每个类别的 p25/p50/p90/p99)。该条揭示了
单个平均值所掩盖的类别内离散——shell/command 的 p50 约 0.85s,但
p99 约 235s,planning 从 p50 约 0.07s 跳到 p99 约 378s,agent/task 从
p50 约 0.18s 攀升到 p99 约 600s。一个类别因此可以有不大的中位数,却有
比它大三到四个数量级的 p99,这正是下一张图在聚合层面量化的长尾行为。
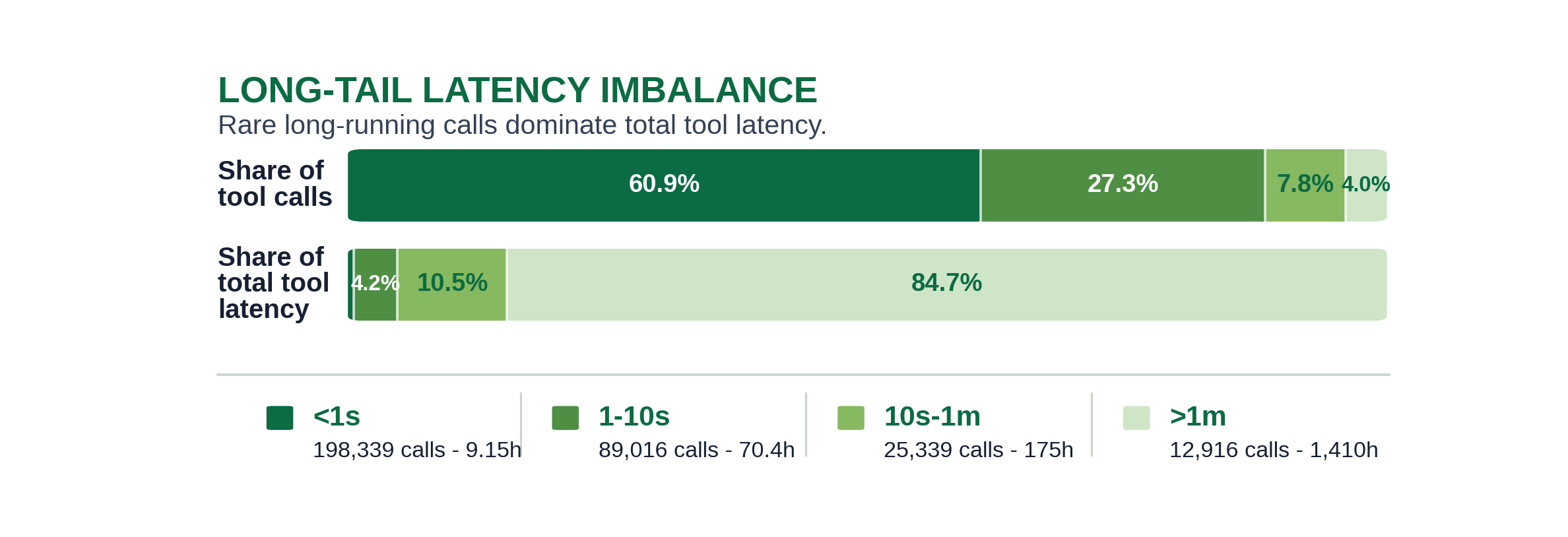
这是醒目的不平衡:上方柱是每个延迟分箱的调用占比,下方
是其总延迟占比,二者颠倒。<1s 分箱占约 61% 的调用却仅占
约 0.5% 的总延迟,而 1–10s 又添了约 27% 的调用却仅占约 4% 的延迟。在另一
端,>1m 分箱仅占约 4% 的调用却占全部工具延迟的约 85%,10s–1m(约 8% 的调用)
贡献剩下的约 11%。因此少数几次慢调用占据了花在工具上时间的
绝大多数——这与按提供商看到的长尾特征相同,现在跨类别
聚合。精确数字见 tool_latency_long_tail_imbalance.csv。
单个工具名众多且因提供商而异;本实验将它们归入跨 Claude Code 和 Codex 含义相同的粗粒度类别,然后报告调用和有效延迟在这些类别间的分布。
方法与假设:
tool_calls(即 UNNEST 后的 tools[])中的条目,而非智能体步骤。other 的映射(Execute command、File write/edit、File read/search、Agent/task、Web/remote/lookup、Other)驱动计数
环图和延迟柱状图;一套 7 桶的展示映射(额外拆分出 Planning)
驱动 dashboard。两套映射都是逐字移植的显式 名称→类别 集合——
tool_category_tool_map.csv 发出已实现的 (category, provider, tool) 分解供
审计。tool_internal_latency_ms(若存在),否则 tool_wall_latency_ms
(遗留的 latency_ms 回退不在归一化 schema 中)。只有正延迟
贡献到延迟求和以及分位数/长尾视图;缺失和非正
延迟被单独计数但排除在求和之外。<1s、1–10s、10s–1m、>1m,以
对比每个桶的调用占比与其总延迟占比。analyze.py 是一个基于共享 trace DuckDB 的 query→fold→plot 流水线:
load_tool_aggregates(con)——一条对 tool_calls ⋈ rounds 的 GROUP BY (provider, tool_name),
返回逐工具的 calls、error_calls,有效/缺失/非正延迟类计数,
以及正延迟求和。提供商/工具名归一化(<unknown-provider> /
<unknown-tool>)在 SQL 中完成,以匹配旧的 loader。load_positive_latency_histogram(con)——正延迟的 (tool_name, latency_ms, count) 行,
在 Python 中展开为分位数所消费的逐类别延迟列表。scan_trace / scan_trace_presentation / scan_trace_long_tail_latency——使用逐字的
category_for_tool / presentation_category_for_tool 映射将逐工具
聚合折叠进粗粒度类别(在整数毫秒延迟上求和与顺序无关)。category_rows / presentation_rows / long_tail_rows 及其 write_*_csv——塑形并发出
四个 CSV。plot_count_ring / plot_latency_bar / plot_dashboard / plot_long_tail_imbalance——
四张图。main() 接入标准 trace_db CLI,并嵌入 PNG sidecar。数据层(解析、代理键、schema)位于 artifacts/utils/trace_db.py;参见
artifacts/utils/DB_SCHEMA.md。
# default merged trace, output next to this README
uv run python artifacts/tool_calls/tool_category_distribution/analyze.py
# a specific trace (materialized to a temp DuckDB cache on first use)
uv run python artifacts/tool_calls/tool_category_distribution/analyze.py -i trace/sample.jsonl
# a prebuilt DB (run_all.py's build-db step passes this), into a chosen dir
uv run python artifacts/tool_calls/tool_category_distribution/analyze.py --db /tmp/trace.duckdb -o /tmp/out
tool_category_count_ring.png——6 个粗粒度类别上调用计数的圆环图。tool_category_latency_bar.png——每个类别的有效延迟求和(小时),带平均值。tool_category_dashboard.png——7 桶展示映射的组合圆环图 + 类别表 + 延迟分位条。tool_latency_long_tail_imbalance.png——<1s … >1m 分箱上的调用占比 vs 延迟占比。tool_category_summary.csv——每个粗粒度类别:调用数、占比、错误率、延迟类计数、
延迟求和/平均。tool_category_tool_map.csv——已实现的 (category, provider, tool_name) 分解。tool_category_dashboard_summary.csv——每个展示类别:调用数、占比、p25/p50/p90/p99
秒。tool_latency_long_tail_imbalance.csv——每个延迟分箱:调用数、调用占比、延迟、延迟
占比。result_analysis.md——生成的运行日志。这些 PNG 是自包含的——每张都嵌入了本 README、CSV 以及绘图代码。用
python artifacts/utils/png_sidecar.py extract <png> 解包。