
工具调用耗时多久——按工具、按提供商区分,以及工具延迟的长尾分布在何处—— 针对 Claude Code 与 Codex?
工具调用耗时多久——按工具、按提供商区分,以及工具延迟的长尾分布在何处—— 针对 Claude Code 与 Codex?
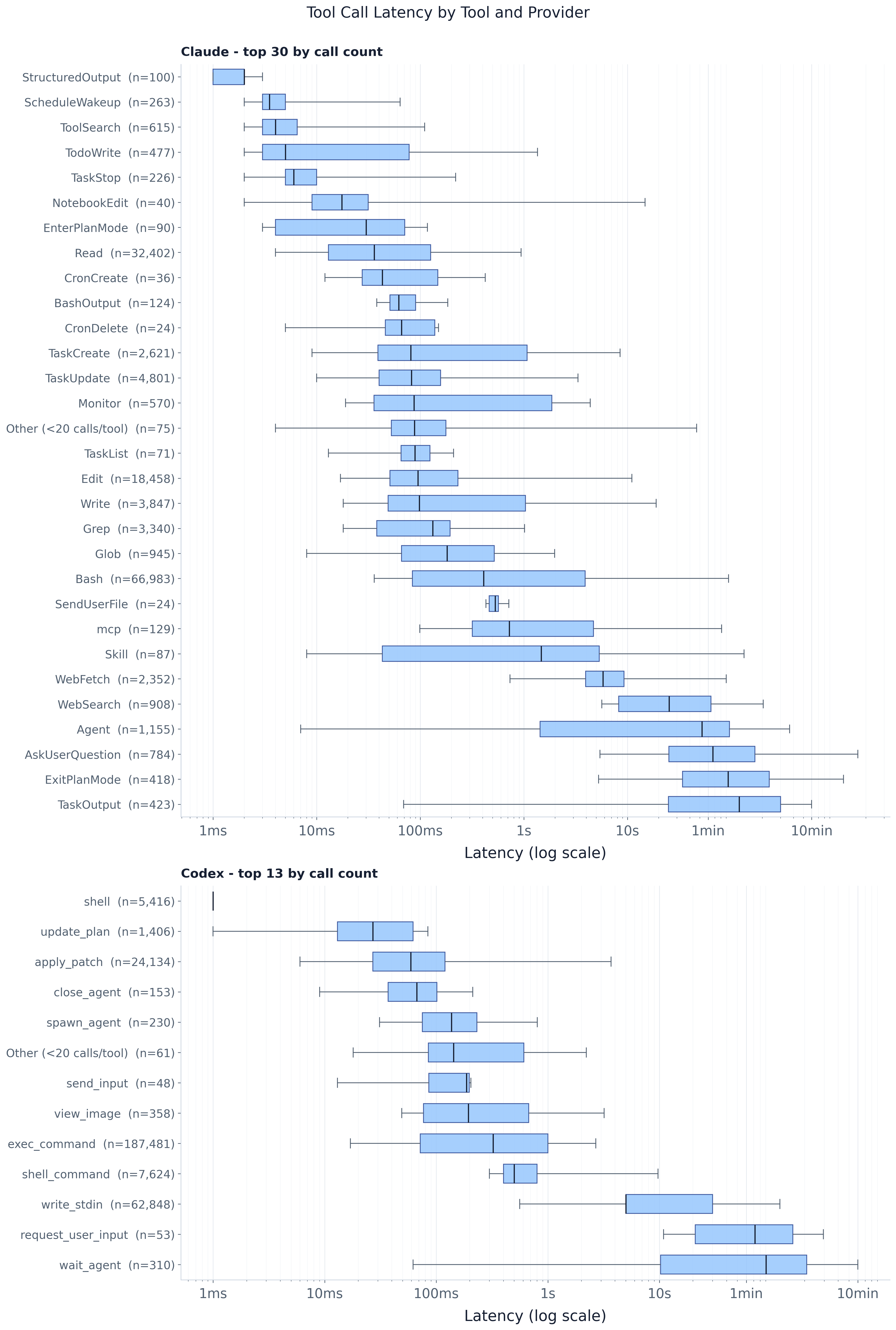
延迟在很大程度上取决于工具类型,而同一类型内部的逐调用离散度很大(论文中的
fig:tool_latency_by_tool_top12)。全 trace 的平均工具调用延迟约为 ~16.8s,但这个
均值掩盖了巨大的结构差异:快速的文件/编辑原语(Read p50 36 ms、Edit p50 95 ms、
Grep、apply_patch)以紧凑的箱聚集在数十至数百毫秒之间,而
阻塞型工具——Agent、AskUserQuestion、shell 执行、wait_agent/request_user_input——
则带着宽得多的箱位于右侧的数秒至数分钟区间。即便在单个工具内部范围也极大:
Claude 的 Bash 从毫秒到分钟都有,但中位数仍保持在亚秒级(p50 ~409 ms)。
箱是 IQR 加中位数线和第 5/95 分位数 whisker(离群值被抑制);工具按调用数
按提供商挑选,再按中位数排序,因此纵向位置读起来就是典型的
慢速程度。结论是:工具类型引导延迟,但单凭它本身不足以预测延迟。
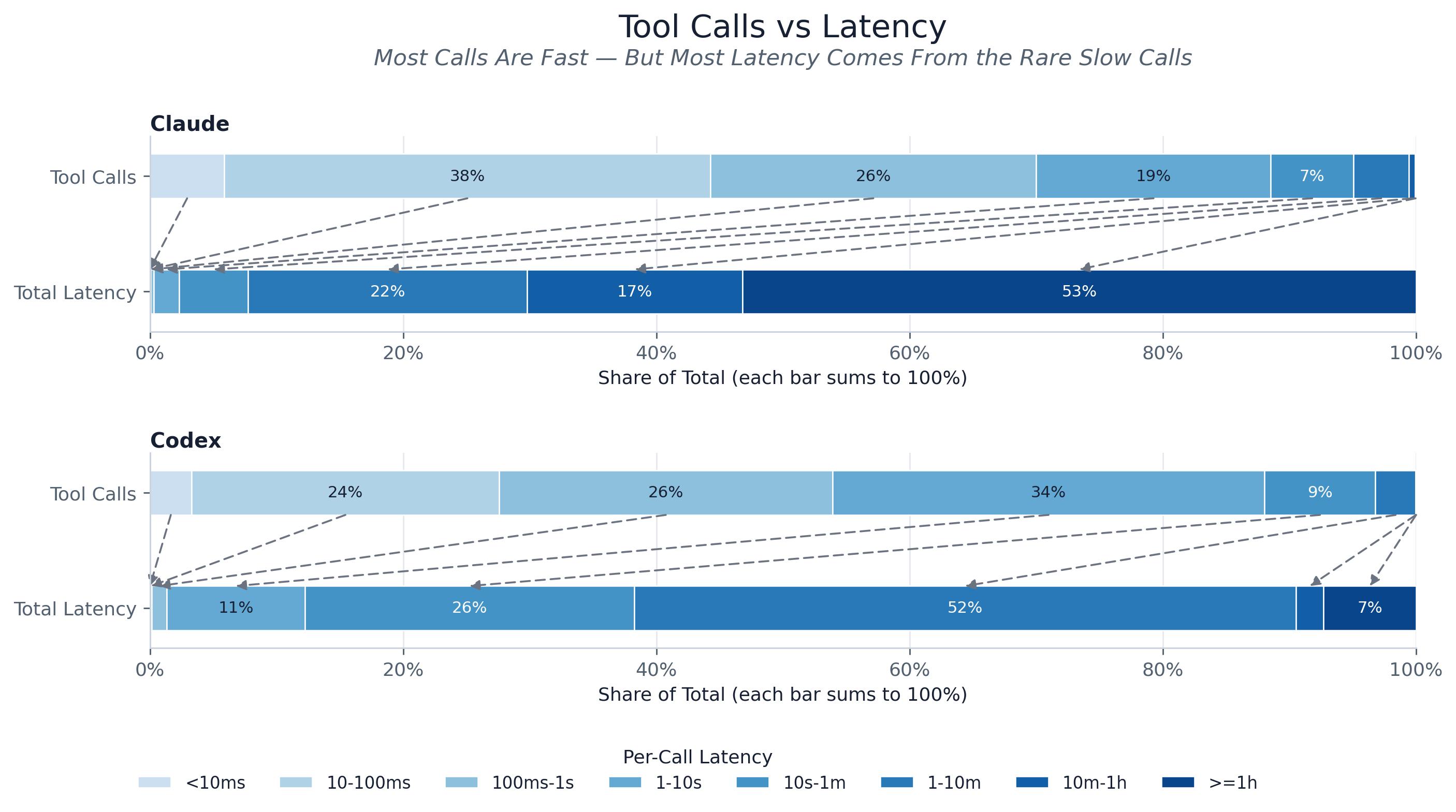
最醒目的非对称性(论文中的 fig:tool_latency_weighted_bins):大多数调用很快,但
大多数时间花在罕见的慢调用上。每个提供商在粗粒度延迟分箱上得到两根
100% 堆叠柱——上方是工具调用占比,下方是延迟求和占比——并用虚线箭头将
每个分箱在两者之间的切片相连。这种分裂既剧烈又因提供商而异:对 Claude 而言,
亚 1s 的调用约占调用的 70%,却占总工具时间的不到 1%,而超过 1 min 的调用只占调用的约 4.9%,
却贡献了约 92% 的时间。Codex 没那么极端但同样由尾部主导——亚 10s
的调用约占调用的 88% 却占时间的约 12%,而超过 1 min 的调用占调用的约 3.1%、占时间的约 61%。
这就是经典的重尾特征:优化中位数工具调用几乎无法撼动总
工具时间;长时间运行的离群值才占据预算的大头。
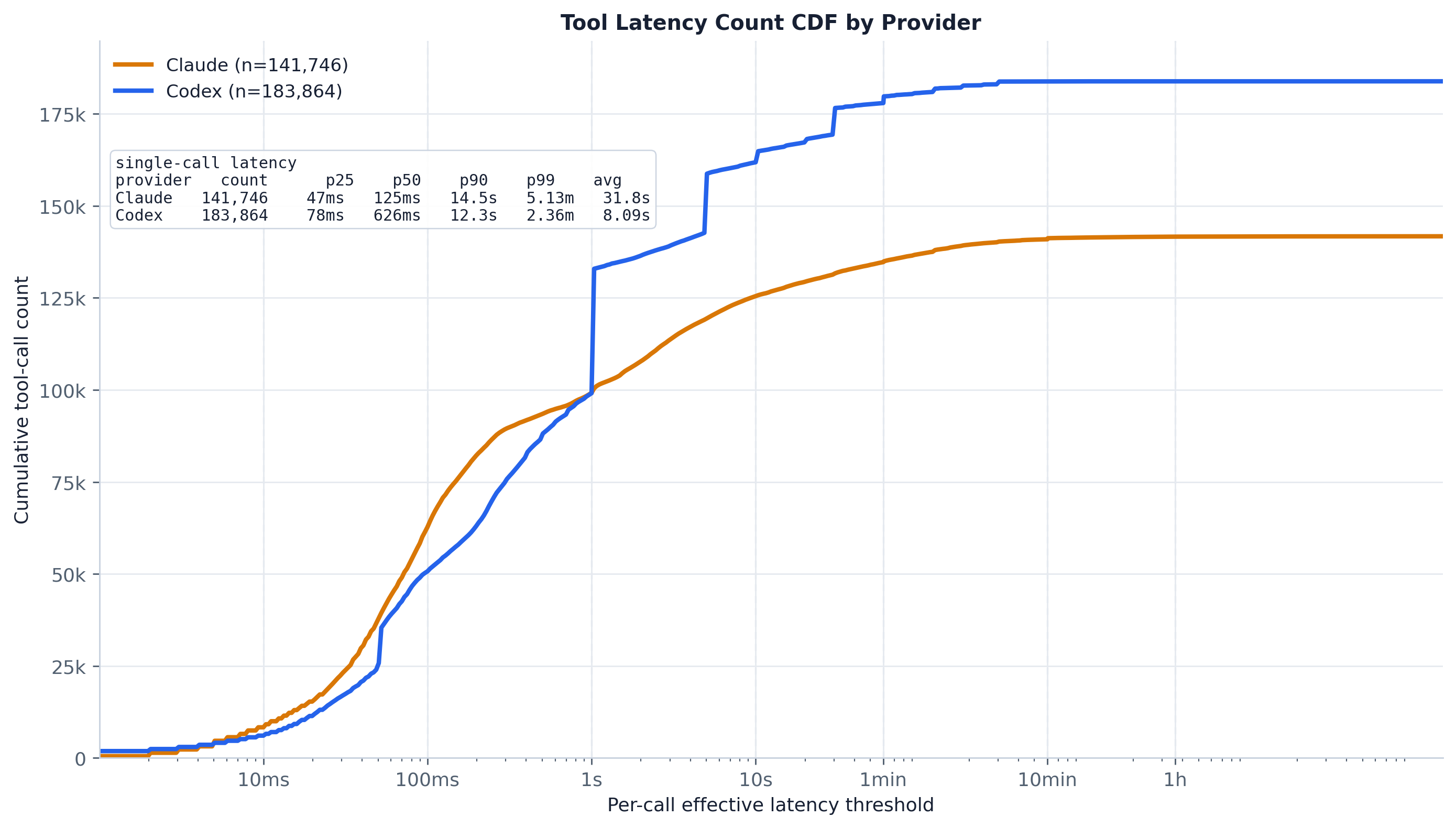
低于或等于某逐调用延迟阈值的累积工具调用计数,按提供商。内嵌表 带有精确的 p25/p50/p90/p99/avg。
write_stdin/exec_command 调用落在相近的延迟上),随后饱和;
Claude 起步更早、更平滑(中位数 ~129 ms vs Codex ~626 ms)。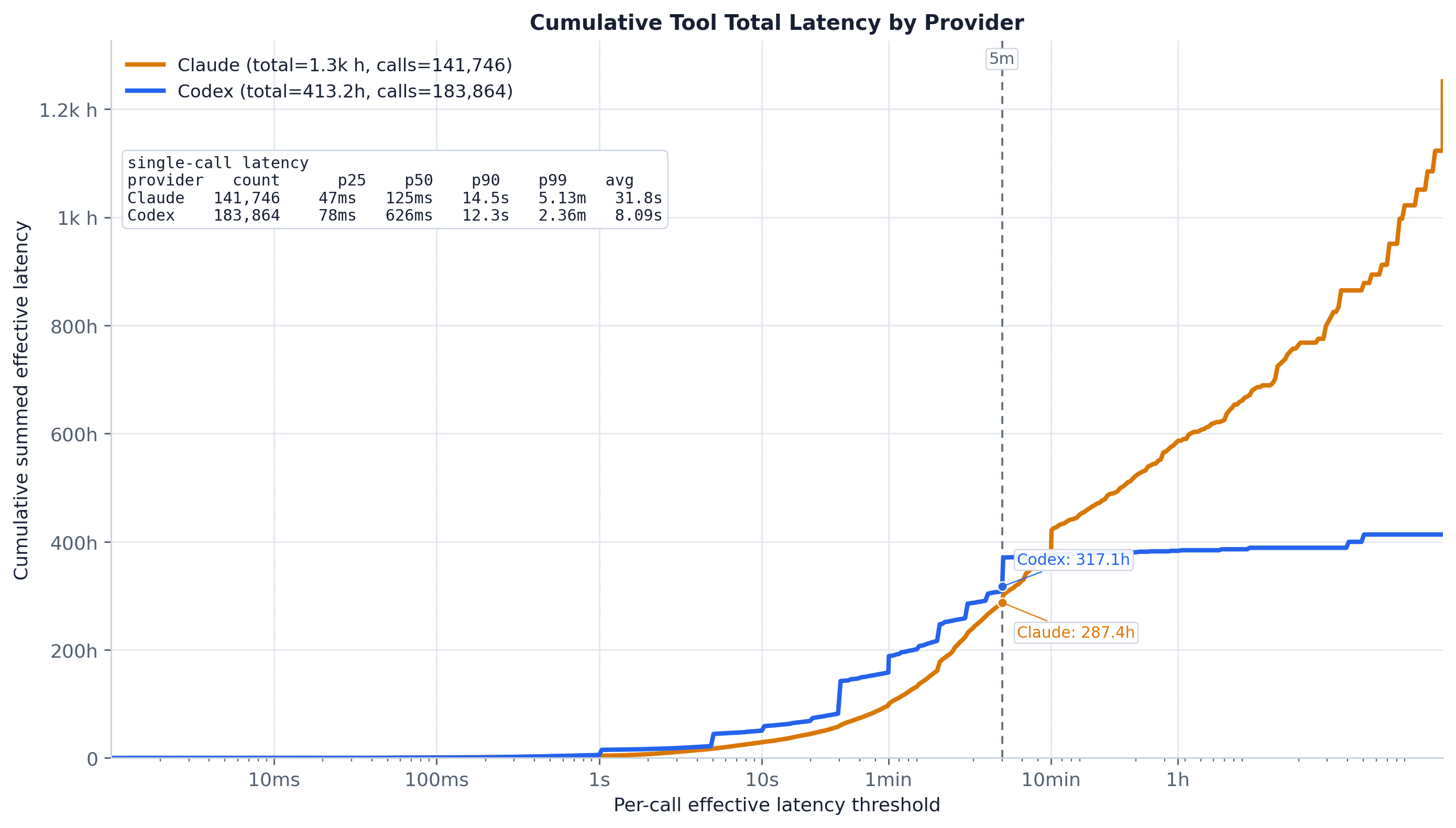
同一阈值扫描,但按延迟求和(以小时计)加权,即聚合工具时间
在何处累积。虚线 5m 参考线标出有多少小时来自比五
分钟更快的调用。
每个智能体步骤都带有一个工具调用的 tools[] 列表,每次调用都有一个测得的延迟。本实验
从四个角度刻画这种逐调用延迟:一个按工具/按提供商的箱线图视图,一个在粗粒度延迟分箱上
的计数-vs-延迟质量分解,以及两条累积 CDF(按调用计数和按延迟求和)随逐调用延迟阈值变化。
方法与假设:
tool_internal_latency_ms(若存在),否则 tool_wall_latency_ms
(= result_at − emitted_at;共享的 trace_db.EFFECTIVE_TOOL_LATENCY_MS_SQL 优先级——
遗留的 latency_ms 字段不在归一化数据中)。内部计时是 runner 上报的
时长(Codex wrapper 的 Wall time、Claude 的 durationMs)。missing_latency;
有效延迟为非正的调用计为 nonpositive_latency
——两者都不进入箱线图、分箱、分位数或 CDF(与旧的 ToolStats 一致)。mcp_ 开头的工具都被别名归入
单个 mcp 桶;那些冗长的带服务器限定名的名称单独看都很罕见。CSV 汇总保留
原始、未别名化的名称。--min-tool-calls-for-plot
(默认 20)的工具被并入一个 Other (<N calls/tool) 箱。CSV 汇总保留
完整的逐工具明细。sampled=False,且 sample_count = 完整的 latency_count
(此前两个最高频工具 exec_command 和 Bash 是被蓄水池采样的)。plot.py 是一个基于共享 trace DuckDB 的轻量级 query→shape→plot 流水线:
_per_tool_query(plot_name_expr, *, by_provider)——共享的逐工具聚合:归一化
工具名(blank/NULL → <unknown-tool>),应用有效延迟优先级,并为每个
桶发出 call/latency_count/missing_latency/nonpositive_latency/error_calls 计数、
latency_sum/min/max、正延迟的精确 list(eff),以及一个首次出现的
first_seen 序号。plot_name_expr 选择原始名(CSV)或 mcp_*→mcp 别名
(图);by_provider 按 rounds.provider 拆分。load_tool_stats(con)——用于汇总 CSV 的全局 {tool_name: ToolStats}(原始名,不折叠),
按首次出现顺序插入,使得稳定的 sort(key=calls) 能复现旧的
dict 顺序的平局判定。load_tool_stats_by_provider(con, *, min_calls)——用于箱线图的按提供商统计,MCP
合并在 SQL 中完成,随后在 Python 中执行罕见工具折叠;真实工具按字母
plot-name 顺序插入(旧的合并-dict 顺序),Other 追加在最后,固定相等调用数的平局。load_tool_latency_values_by_provider(con)——{provider: [positive latency, …]},喂给两条
CDF(精确,无蓄水池)。load_tool_latency_bins(con, *, by_provider)——8 个粗粒度 TOOL_LATENCY_BINS_MS 半开分箱
(call/error 计数 + 延迟求和),全局与按提供商。plot_* / write_*——四张图和四个 CSV。main()——接入标准 trace_db CLI(--db | -i/--input | -o/--output-dir),并嵌入
自包含的 PNG sidecar。matplotlib 3.9 的 labels→tick_labels 箱线图 kwarg 改名由 _BOXPLOT_LABEL_KW
垫片处理,使该图在 Pyodide(web 端 Analyze
页签)捆绑的 matplotlib 3.8.x 下也能渲染。数据层(解析、代理键、schema)位于
artifacts/utils/trace_db.py;参见 artifacts/utils/DB_SCHEMA.md。
# default merged trace, output next to this README
uv run python artifacts/tool_calls/tool_latency_distribution/plot.py
# a specific trace (materialized to a temp DuckDB cache on first use)
uv run python artifacts/tool_calls/tool_latency_distribution/plot.py -i trace/sample.jsonl
# a prebuilt DB (run_all.py's build-db step passes this), into a chosen dir
uv run python artifacts/tool_calls/tool_latency_distribution/plot.py --db /tmp/trace.duckdb -o /tmp/out
实用参数:--top-tools(每个面板最多箱数,默认 30)、--min-tool-calls-for-plot
(罕见工具折叠阈值,默认 20)。
写入 -o(默认本文件夹):
tool_latency_by_tool.png——按提供商的箱线/whisker 面板,展示逐调用延迟按工具分布。tool_latency_summary.csv——完整的逐工具统计(原始名):calls、latency_count、
missing_latency、nonpositive_latency、error_calls、mean_ms、min_ms、p50/p90/p99_ms、
max_ms、sample_count、sampled、providers。tool_latency_weighted_bins.png / .csv——在 8 个粗粒度延迟分箱上的工具调用计数 vs 延迟求和占比。tool_latency_count_cdf_by_provider.png / .csv——累积工具调用计数 ≤ 某延迟
阈值,按提供商。tool_total_latency_cdf_by_provider.png / .csv——来自 ≤ 某阈值的调用的累积延迟求和,按提供商。每张 PNG 都是自包含的——它嵌入了本 README、CSV 以及绘图代码。用
python artifacts/utils/png_sidecar.py extract <png> 解包。