
在所有工具调用中,哪些工具种类占据了最多的总有效时间—— 分别针对 Claude Code 和 Codex?
在所有工具调用中,哪些工具种类占据了最多的总有效时间—— 分别针对 Claude Code 和 Codex?
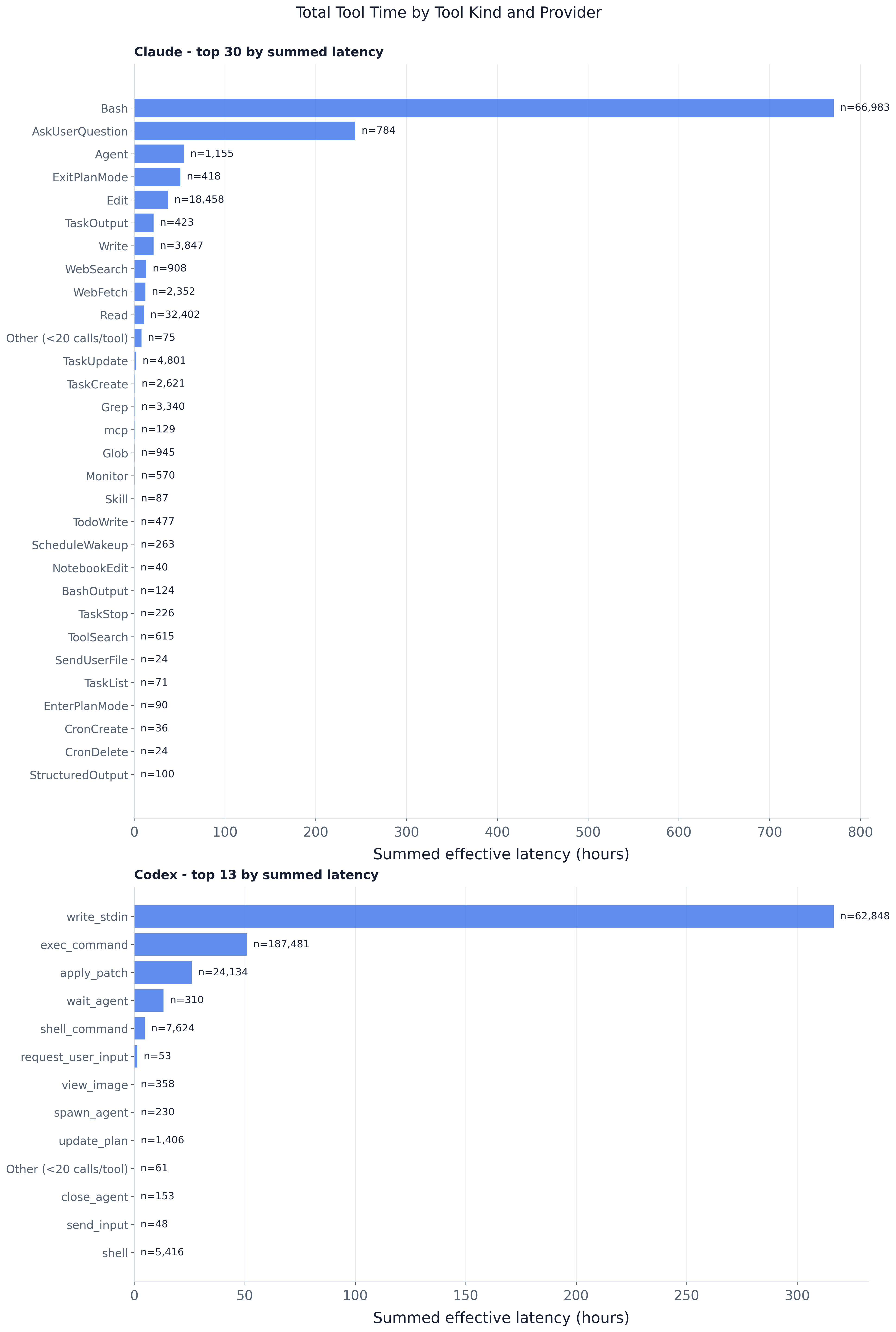
聚合的工具执行时间由少数几个工具种类主导,而非散布在整个
词汇表中。排名按延迟求和(标注了 n= 调用计数),这区分了
通往顶端的两条路径:被持续调用对比单次很慢。Claude 的 Bash
以 67k 次调用中的约 771h 领先一切(占全部工具时间的约 46%)——既高频又有长尾——
紧随其后的是 Codex 的 write_stdin,约 317h。第三根柱暴露了另一种机制:Claude 的
AskUserQuestion 仅靠 784 次调用就达到约 243h,因为每一次都阻塞等待人类
(平均约 19 min/call);Agent(约 55h)和 ExitPlanMode(约 51h)是类似的慢-但-罕见的阻塞者。相比
之下,Codex 的 exec_command——被调用最多的单个工具,达 187k 次调用——仅合计约 51h,
因为每次调用都很廉价。由于延迟在并行调用上可加,这些都是归因到的
工作量,而非墙钟会话时间;CSV(latency_share、avg_latency_ms)有精确的
数字,包括折叠进 Other 的尾部。
trace 中的每个智能体步骤都带有一个工具调用的 tools[] 列表,每次调用都有一个测得的延迟。
本实验将该延迟归因到工具种类,并追问聚合的工具执行
时间花在哪里,为每个提供商渲染一个水平柱状图面板,工具按延迟求和排序
(每根柱都标注其调用计数 n)。
方法与假设:
tool_internal_latency_ms(若存在),否则 tool_wall_latency_ms
(共享的 trace_db.EFFECTIVE_TOOL_LATENCY_MS_SQL 优先级;遗留的 latency_ms 字段
不在归一化数据中)。只有严格为正的延迟才贡献到某工具的
求和/平均时间;没有有效延迟的调用被计为 missing_latency_calls。tool_calls(即 UNNEST 后的 tools[])中的条目,而非智能体步骤。mcp_ 开头的工具都被别名归入
单个 mcp 桶;那些冗长的带服务器限定名的名称单独看都很罕见。CSV 保留原始
未别名化的名称。--min-tool-calls-for-plot
(默认 20)的工具被汇总进一个 Other (<N calls/tool) 柱。CSV 保留
完整的逐工具明细——数据中不丢弃任何内容,只是从图中省略。plot.py 是一个基于共享 trace DuckDB 的轻量级 query→shape→plot 流水线:
_tool_time_query(plot_name_expr, *, by_provider)——共享的聚合:归一化工具
名(blank/NULL → <unknown-tool>),应用有效延迟优先级,并发出
逐桶的 calls、latency_count、missing_latency、error_calls、latency_sum,外加一个
首次出现的 first_seen 序号用于确定性的平局判定。plot_name_expr 选择
原始名(CSV)或 mcp_*→mcp 别名(图);by_provider 添加 rounds.provider join。load_tool_time(con)——用于 CSV 的全局 {tool_name: ToolTimeStats}(原始名,不折叠)。load_tool_time_by_provider(con, *, min_calls)——按提供商统计,MCP 合并在
SQL 中完成,罕见工具折叠在 Python 中完成(求和与顺序无关)。plot_tool_total_time_by_kind(...)——按提供商的延迟求和面板。write_tool_total_time_by_kind(...)——完整明细 CSV。main()——将标准 trace_db CLI(--db | -i/--input | -o/--output-dir)接到
上述逻辑,并嵌入自包含的 PNG sidecar。ToolTimeStats 的平局由 first_seen(最小全局调用序号)打破,因此输出在各次
DB 构建间保持稳定——GROUP BY 顺序则不然。数据层(解析、代理键、schema)位于
artifacts/utils/trace_db.py;参见 artifacts/utils/DB_SCHEMA.md。
# default merged trace, output next to this README
uv run python artifacts/tool_calls/tool_time_by_kind/plot.py
# a specific trace (materialized to a temp DuckDB cache on first use)
uv run python artifacts/tool_calls/tool_time_by_kind/plot.py -i trace/sample.jsonl
# a prebuilt DB (run_all.py's build-db step passes this), into a chosen dir
uv run python artifacts/tool_calls/tool_time_by_kind/plot.py --db /tmp/trace.duckdb -o /tmp/out
实用参数:--top-tools(每个面板最多柱数,默认 30)、--min-tool-calls-for-plot
(罕见工具折叠阈值,默认 20)。
写入 -o(默认本文件夹):
tool_total_time_by_kind.png——按提供商分面板的每个工具种类的总有效时间。tool_total_time_by_kind.csv——完整的逐工具总量:tool_calls、valid_latency_calls、
missing_latency_calls、error_calls、total_latency_ms/_s/_hours、latency_share、
avg_latency_ms。该 PNG 是自包含的——它嵌入了本 README、CSV 以及绘图代码。用
python artifacts/utils/png_sidecar.py extract <png> 解包。