
After removing the previous step’s model output from this step’s newly appended tokens, how much external context growth (new user/tool content + framing) is actually added per step?
After removing the previous step’s model output from this step’s newly appended tokens, how much external context growth (new user/tool content + framing) is actually added per step?
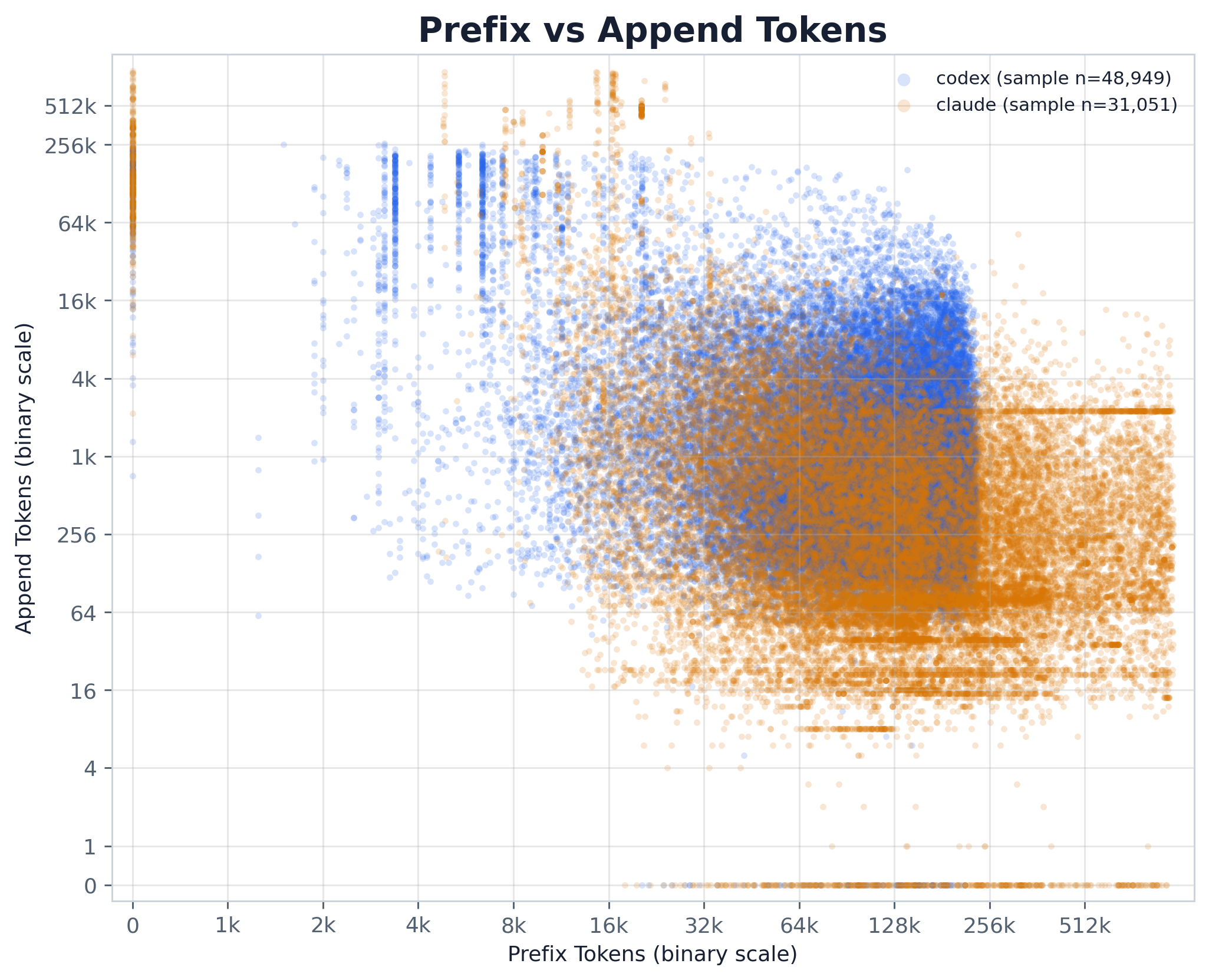
A prefix-vs-adjusted-append scatter on base-2 log axes, one colored series per provider. The x-axis is the reused cached prefix of the current step; the y-axis is its adjusted append — the freshly charged tokens after subtracting the prior step’s replayed output. The takeaways:
raw_append vs adjusted_append, and the clipped_after_subtract share where the subtraction
drove the append to zero).--pair-sample-size points), so it conveys
joint structure, not exact density; read the CSV for the per-provider quantiles.The previous assistant response is normally replayed into the next prompt, so it shows up inside the
next step’s newly_append_tokens (the cache-write / freshly-charged slice). Subtracting it isolates
the genuinely new content. The metric is an adjacent-step policy applied within a session:
the steps of each session are walked in order, and each step is compared to the step immediately
before it (round_index differing by exactly 1).
For each such (previous, current) pair the experiment derives, on current:
max(0, newly_append_tokens − prior-step output proxy), plus the
intermediate signed_adjusted_append (pre-clip) and a clipped_after_subtract flag for pairs the
subtraction drove negative.Method and assumptions:
--subtract-policy (default claude-and-gpt55) decides which pairs get the subtraction.
Only Claude and Codex gpt-5.5 carry their prior output — including reasoning — forward into
the next step’s append, so only those previous rows are subtracted. gpt-5.4 and earlier Codex
models do not carry reasoning forward, so subtracting it would over-count and spuriously clip the
append to 0; those rows are left raw. all subtracts every provider/model and is kept only for
comparison.--subtract-output (default total) decides what quantity is subtracted from the selected
rows: total subtracts the full output_tokens (visible + reasoning), correct for Claude/gpt-5.5
since they replay reasoning; visible-for-codex instead subtracts
output_tokens − reasoning_output_tokens for Codex. See ../../../docs/prompt_cache_accounting.md
for the cache-accounting evidence.session_id in first-appearance (file) order, then stably
sorted by round_index, so ties keep file order. The shared DuckDB surrogate key ingest_seq
(= round_pk) is that file order, so pulling ORDER BY ingest_seq and grouping in Python
reproduces both the per-session row order and the session-visitation order byte-for-byte.(n−1)·q), matching np.percentile’s default.--pair-sample-size, default 80k). Because the sampler is
preserved and fed in file order (ingest_seq), it retains exactly the same points as the
pre-migration loader — the scatter figure is byte-for-byte unchanged on a fixed trace.plot.py is a query→shape→plot pipeline over the shared trace DuckDB:
load_adjusted_pairs(con, *, subtract_output, subtract_policy, sample_size, seed) — pulls the
step-level columns ORDER BY ingest_seq, drops rows with a non-string provider/session_id or a
non-integer round_index (the old loader’s validity gate; in the pinned-schema DB these are the
NULL rows), groups into rows_by_session preserving file order, stably sorts each session by
round_index, then walks adjacent pairs. It returns the reservoir-sampled (provider, prefix, adjusted_append) scatter sample, the full per-provider:metric summary_values lists, and a stats
Counter.output_proxy(...) / should_subtract_previous_output(...) — the --subtract-output quantity and
the --subtract-policy row selection, unchanged from pre-migration.plot_adjusted_prefix_append(...) — the prefix-vs-adjusted-append scatter (binary token axes,
per-provider series), matplotlib behavior unchanged.write_summary_csv(...) — the per-provider/metric quantile CSV, using the legacy
median/percentile/fmt helpers so values match the pre-migration run exactly.main() — wires the standard trace_db CLI (--db | -i/--input | -o/--output-dir) and embeds
the self-contained PNG sidecar.The data layer (parsing, surrogate keys, schema) lives in artifacts/utils/trace_db.py; see
artifacts/utils/DB_SCHEMA.md.
# default merged trace, output next to this README
uv run python artifacts/llm_generation/adjusted_prefix_append/plot.py
# a specific trace (materialized to a temp DuckDB cache on first use)
uv run python artifacts/llm_generation/adjusted_prefix_append/plot.py -i trace/sample.jsonl
# a prebuilt DB (run_all.py's build-db step passes this), into a chosen dir
uv run python artifacts/llm_generation/adjusted_prefix_append/plot.py --db "$TMPDIR/trace.duckdb" -o "$TMPDIR/out"
Useful flags: --subtract-policy (claude-and-gpt55 / all), --subtract-output
(total / visible-for-codex), --pair-sample-size (scatter subsample, default 80000),
--max-groups (max plotted providers, default 8).
Written to -o (default this folder):
prefix_vs_adjusted_append_sample.png — prefix vs adjusted-append scatter (reservoir subsample).prefix_vs_adjusted_append_summary.csv — per-provider/metric quantiles (count, median,
p90, p95, p99, min, max) over all pairs, for the raw_append, previous_output,
signed_adjusted_append, adjusted_append, subtracted_pair, and clipped_after_subtract
metrics.The PNG is self-contained — it embeds this README, the summary CSV, and the plotting code
(plot.py + shared artifacts/utils/ modules). Unpack with
uv run python artifacts/utils/png_sidecar.py extract <png>.