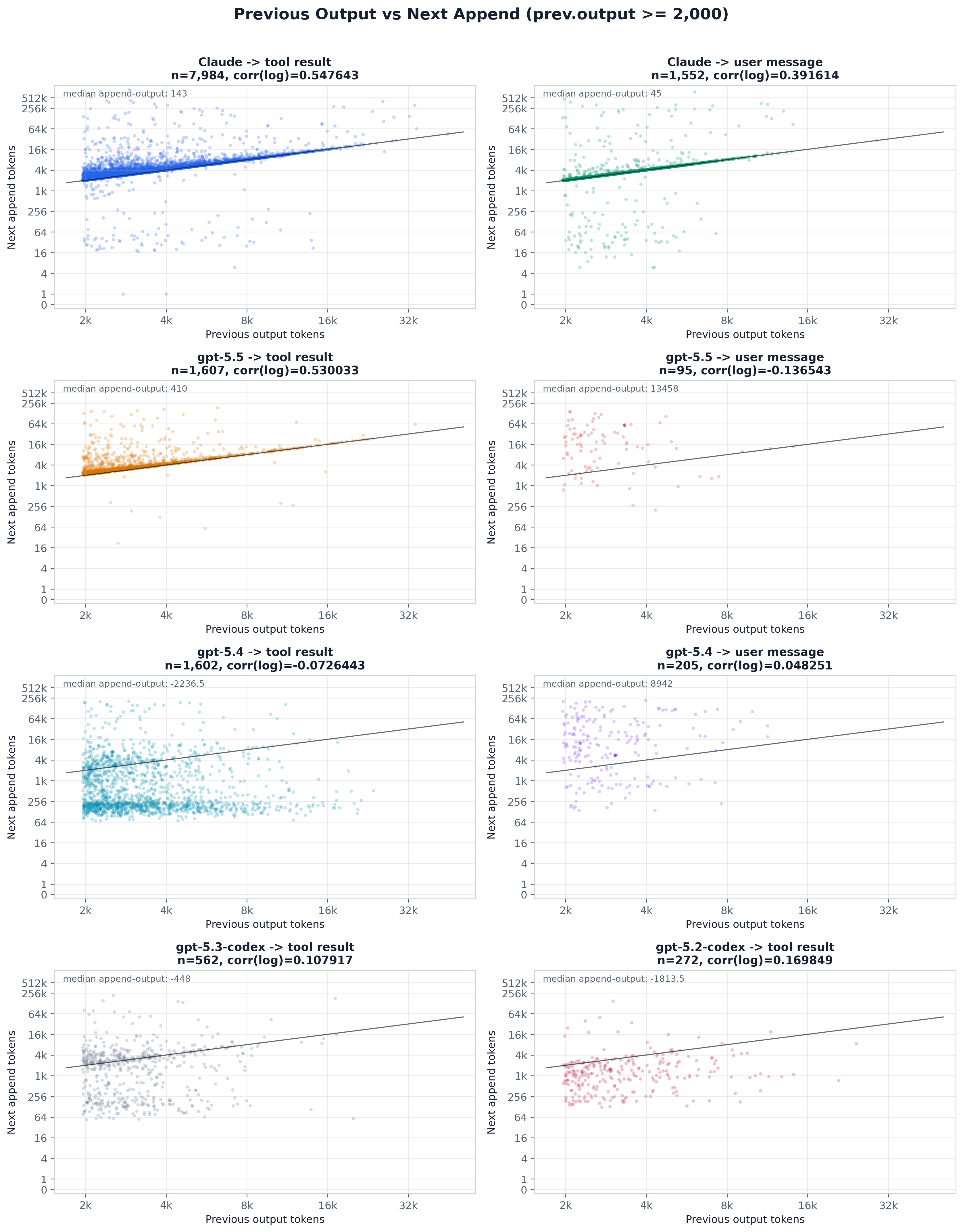
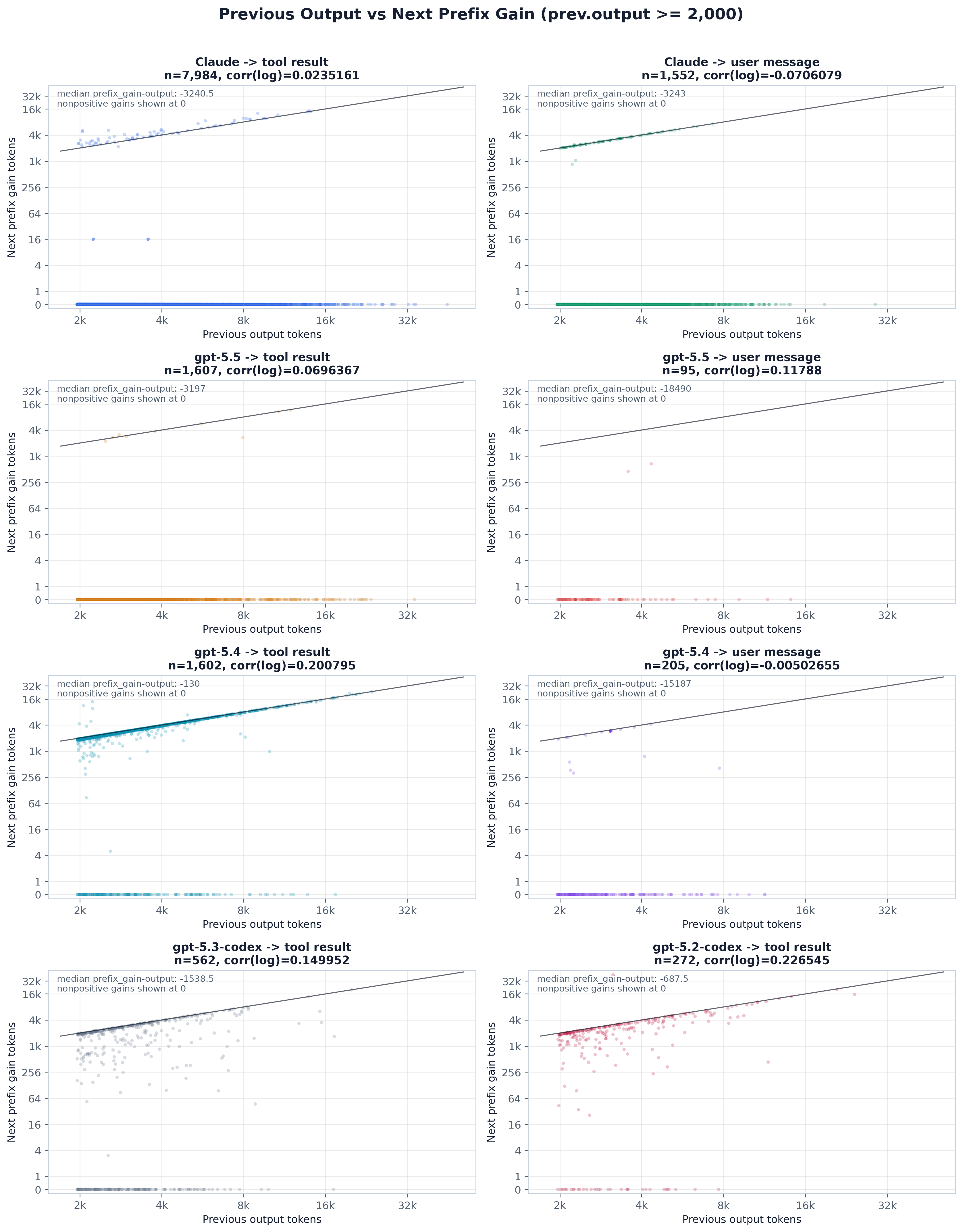
A prior step’s output can enter the next step’s prompt two ways (the paper’s fig:output_attribution).
Under (a) output-cached, the serving system keeps the KV it produced during decode, so the prior
step’s whole composition — prefix, append, and output (10 + 2 + 4 = 16 units) — folds into the next
step’s cached prefix, which then adds only its own fresh append and output. Under (b) output-resend,
only the prior prefix and append are cached (10 + 2 = 12); the prior output is dropped from the cache
and re-sent as part of the next step’s billed append (4 + 1 = 5), so the tell is that the re-sent
output makes the next append longer than the prior output. We separate the two cases by their
invariants — output-cached makes the next prefix gain track the prior output, output-resend makes
the next append absorb it. Applied per model on prior outputs ≥2k tokens (the paper’s
fig:model_merged_output_attribution), Claude and gpt-5.5 come out output-resend (≈98–99%
append-side, prefix-close near zero) while gpt-5.4 is output-cached (~82% prefix-close, only ~13%
append-side). The likely driver is KV-cache pool management in PD-disaggregated serving: output-cached
must transfer decode-produced KV back to shared storage, whereas output-resend lets decode stay
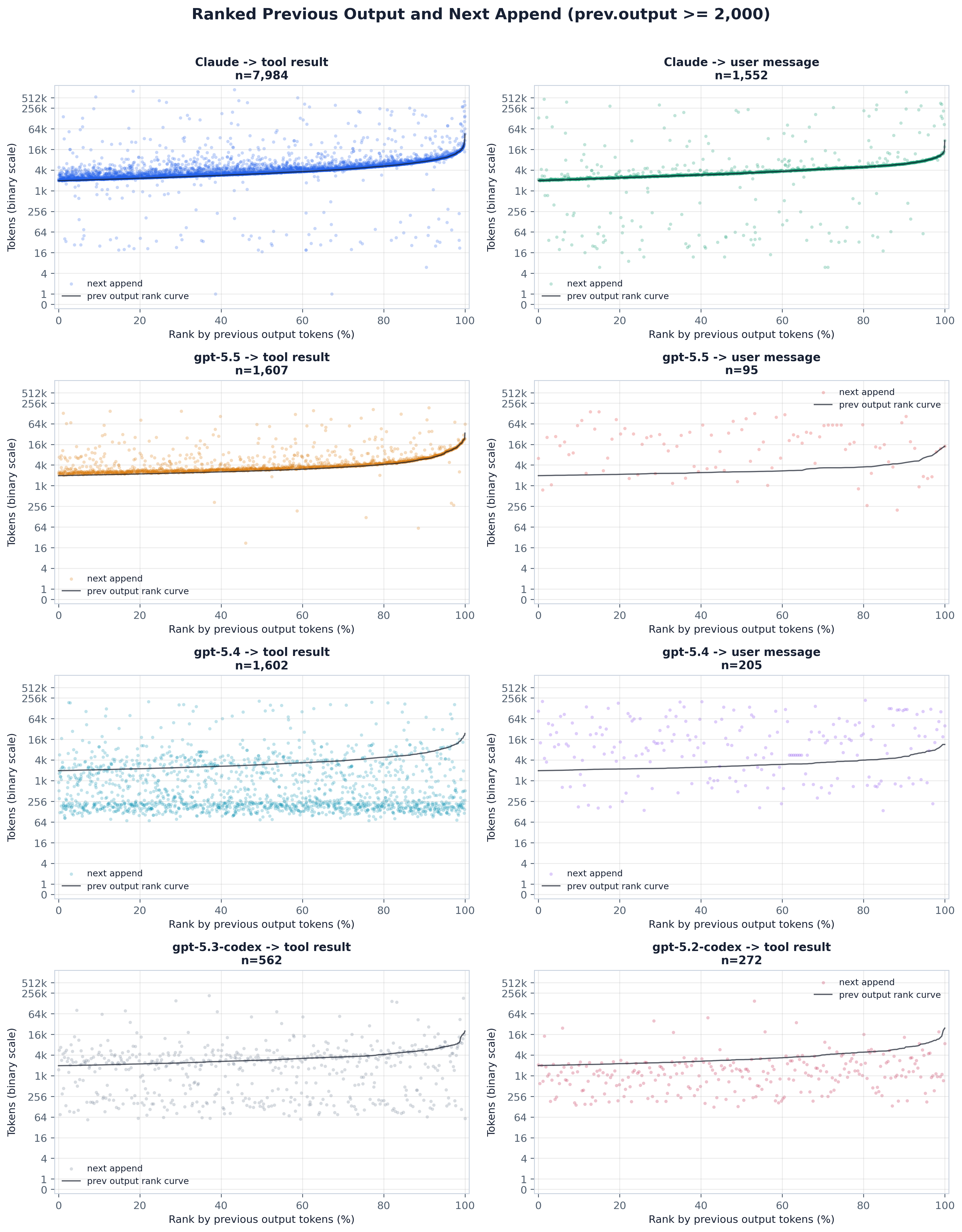
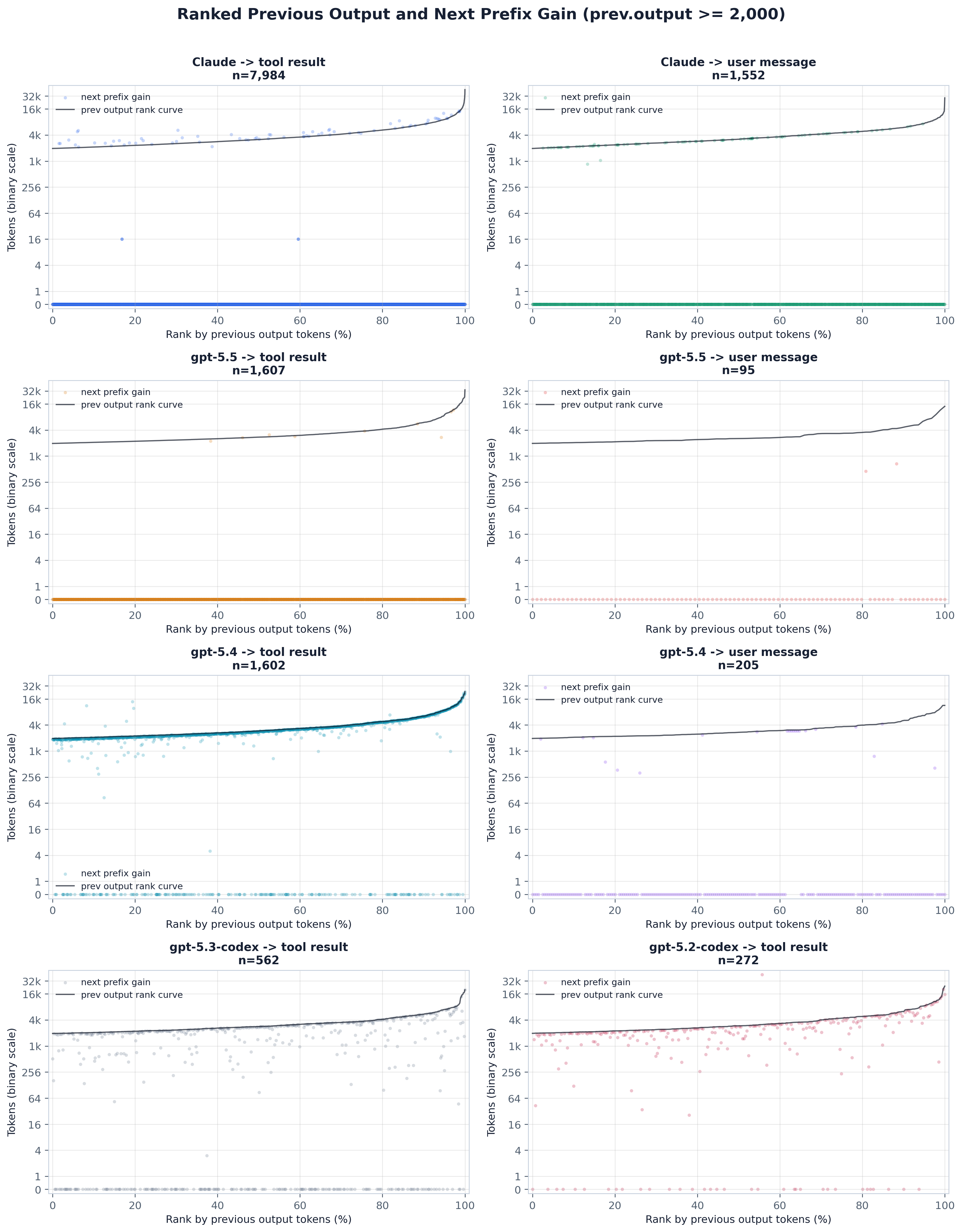
read-only and simply re-prefills the prior output. The scatter and ranked panels below are that test,
split by scenario and by the ≥2k / ≥4k output threshold.