
How long do tool calls take, per tool and per provider, and where does the long tail of tool latency live — for Claude Code vs Codex?
How long do tool calls take, per tool and per provider, and where does the long tail of tool latency live — for Claude Code vs Codex?
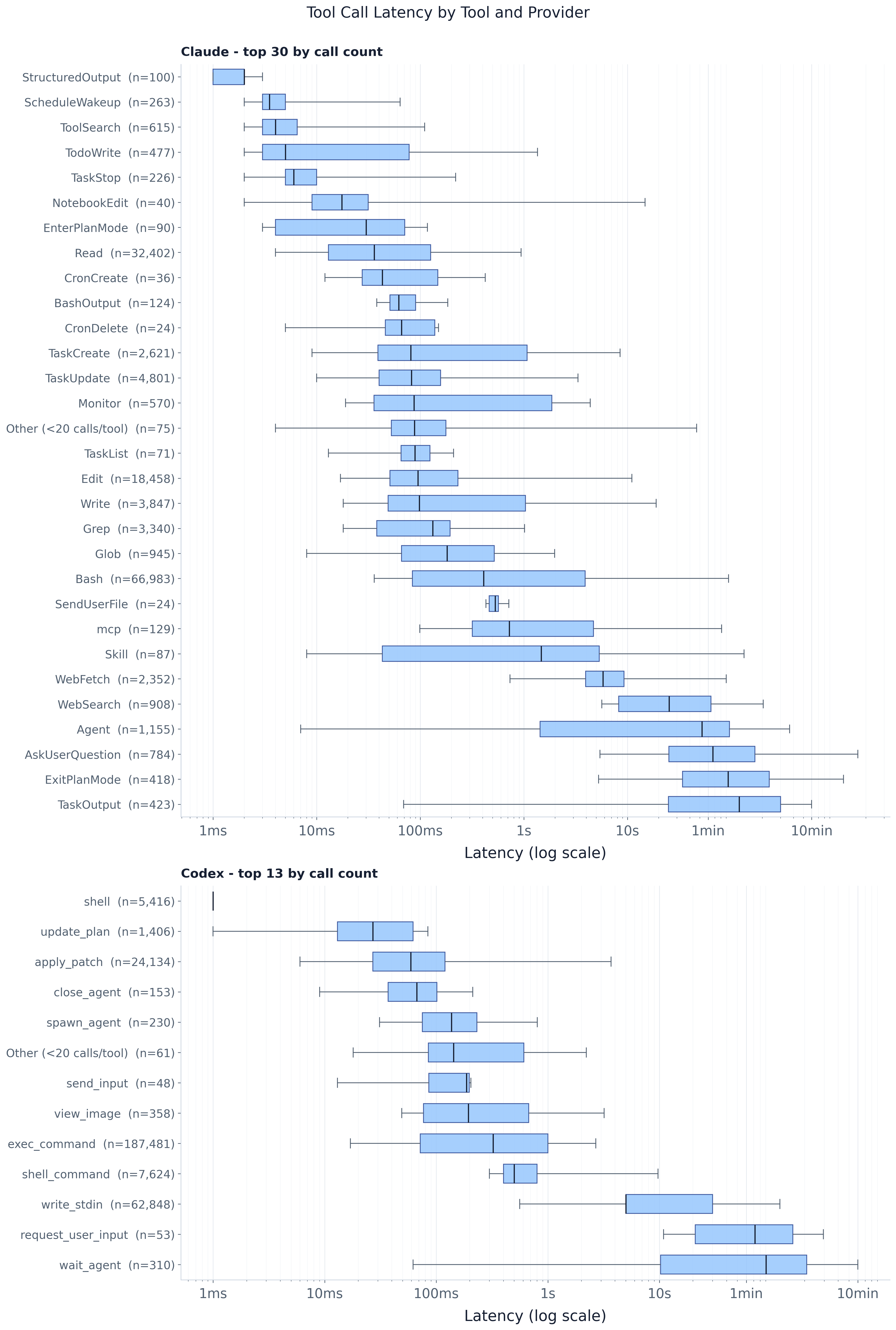
Latency depends heavily on tool type, and the per-call spread within a type is large (the paper’s
fig:tool_latency_by_tool_top12). The distribution hides enormous structure: fast file/edit
primitives (Read p50 27 ms, Edit p50 75 ms,
Grep, apply_patch) cluster in the tens-to-hundreds of milliseconds with tight boxes, while
blocking tools — Agent, AskUserQuestion, shell execution, wait_agent/request_user_input —
sit seconds-to-minutes to the right with much wider boxes. Even inside one tool the range is huge:
Claude’s Bash runs from milliseconds to minutes yet keeps a sub-second median (p50 329 ms).
Boxes are the IQR with the median line and 5th/95th whiskers (outliers suppressed); tools are
picked per provider by call count then ordered by median, so vertical position reads as typical
slowness. The takeaway: tool type guides latency but is not sufficient on its own to predict it.
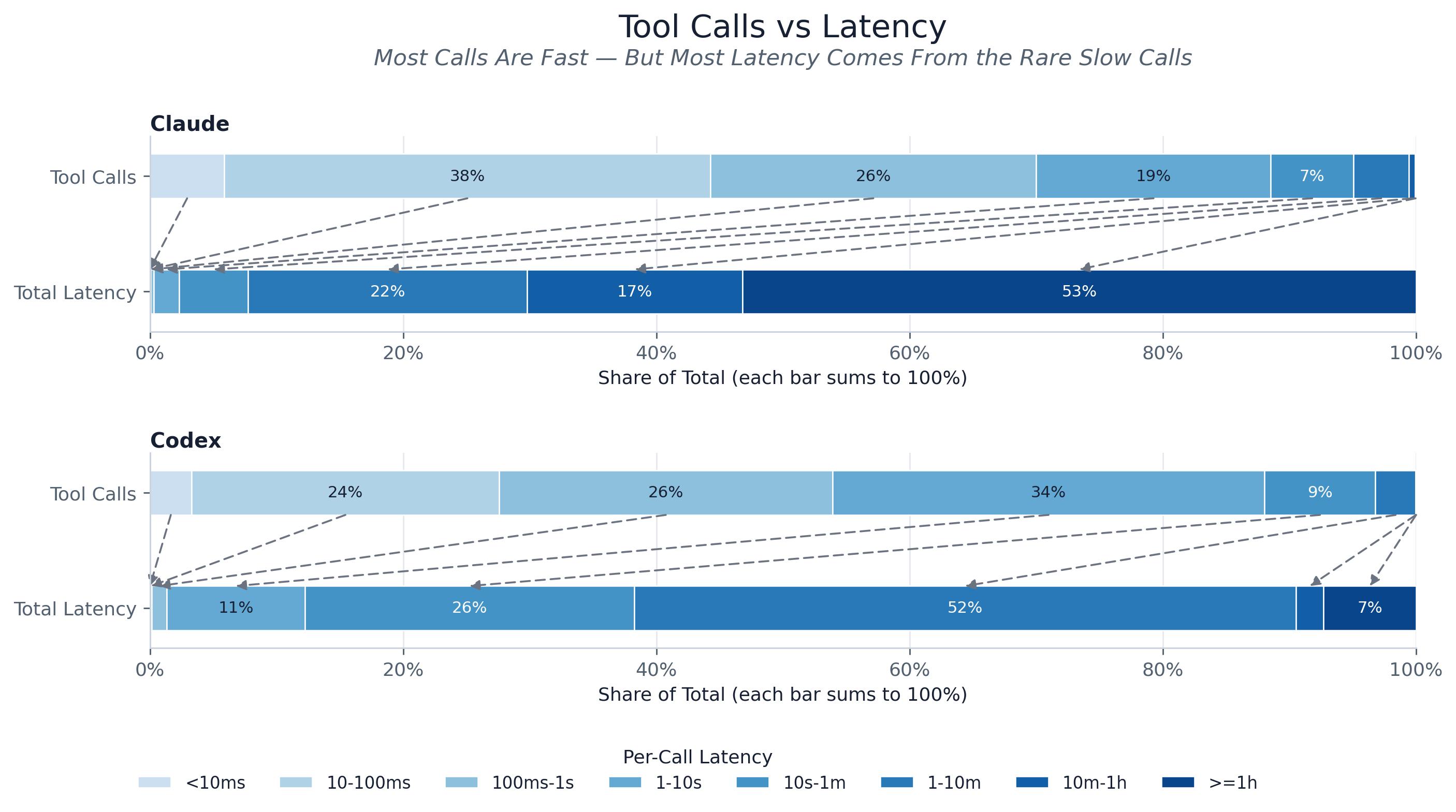
The headline asymmetry (the paper’s fig:tool_latency_weighted_bins): most calls are fast, but
most time is spent in the rare slow calls. Each provider gets two 100%-stacked bars over the
coarse latency bins — tool-call share on top, summed-latency share below — with dashed arrows tying
each bin’s slice between the two. In the merged trace, sub-1s calls are 61.3% of positive-latency
calls but only 0.6% of total tool time, while calls over 1 min are only 3.4% of calls yet contribute
83.6% of the time. This is the classic heavy-tail signature: optimizing the median tool call barely moves total
tool time; the long-running outliers own the budget.
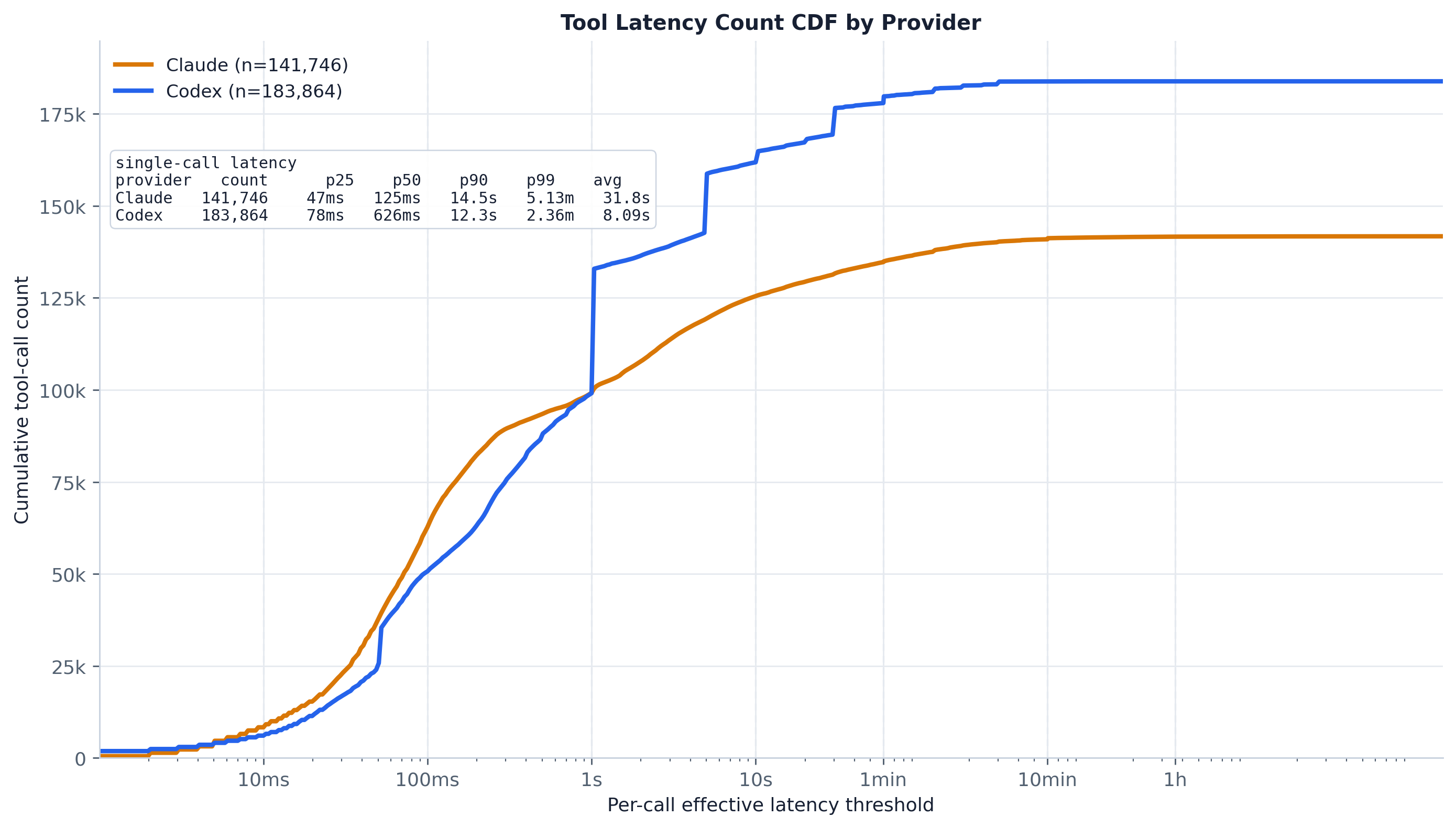
Cumulative tool-call count at or below a per-call latency threshold, per provider. The inset table carries exact p25/p50/p90/p99/avg.
write_stdin/exec_command calls land at similar latencies), then saturates;
Claude rises earlier and more smoothly (median ~129 ms vs Codex ~626 ms).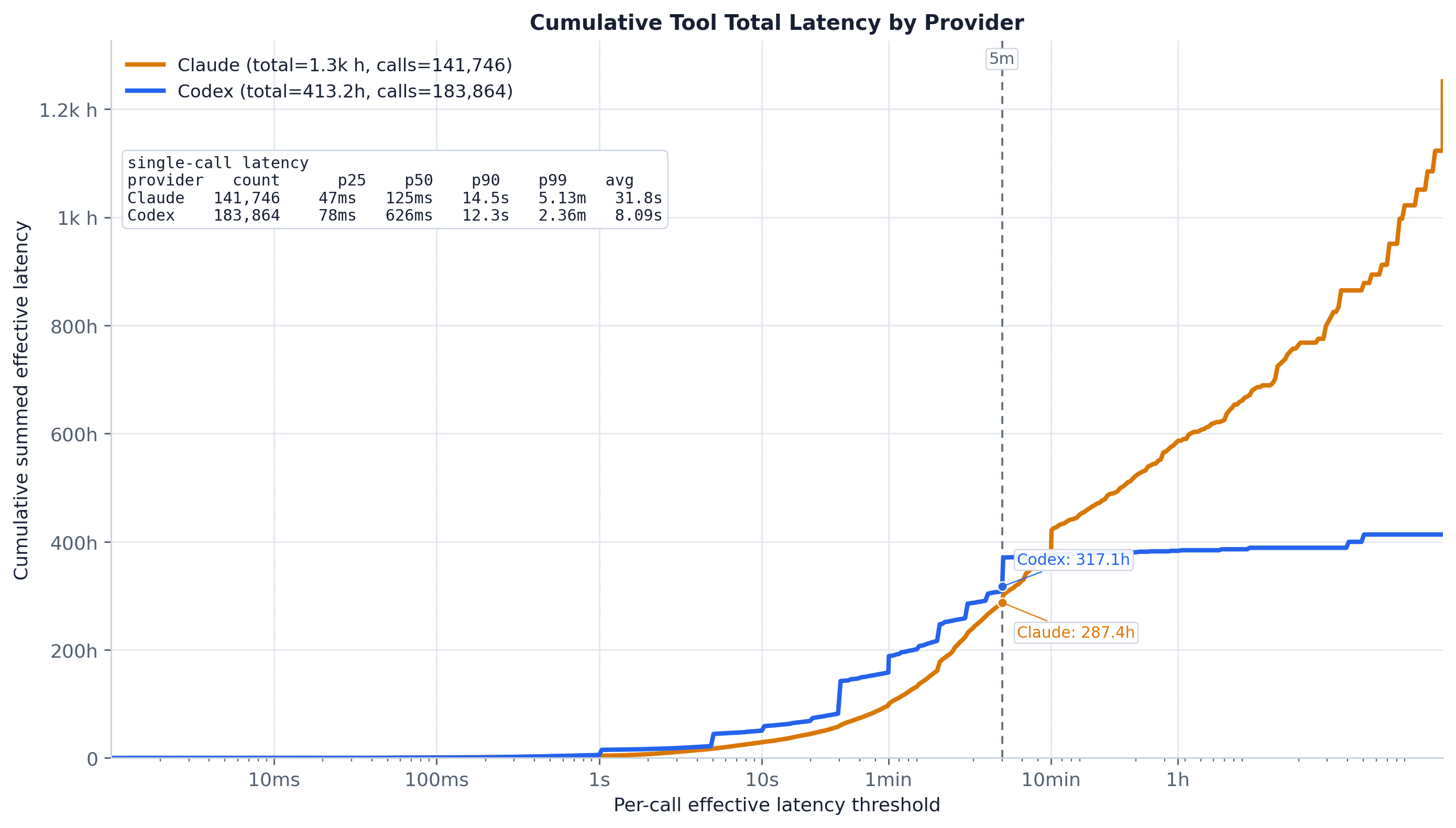
The same threshold sweep weighted by summed latency (in hours), i.e. where the aggregate tool time
accumulates. The dashed 5m reference marks how many hours come from calls faster than five
minutes.
Every agent step carries a tools[] list of tool calls, each with a measured latency. This experiment
profiles that per-call latency four ways: a per-tool/per-provider box-and-whisker view, a
count-vs-latency mass breakdown over coarse latency bins, and two cumulative CDFs (by call count and
by summed latency) over the per-call latency threshold.
Method and assumptions:
tool_internal_latency_ms if present, else tool_wall_latency_ms
(= result_at − emitted_at; the shared trace_db.EFFECTIVE_TOOL_LATENCY_MS_SQL precedence — the
legacy latency_ms field is not in the normalized data). Internal timing is the runner-reported
duration (Codex wrapper Wall time, Claude durationMs).missing_latency; a call with a non-positive effective latency is nonpositive_latency
— neither enters the boxplots, bins, percentiles, or CDFs (matching the old ToolStats).mcp_ is aliased to a
single mcp bucket; the long server-qualified names are individually rare. CSV summaries keep the
raw, unaliased names.--min-tool-calls-for-plot
provider-local calls (default 20) fold into one Other (<N calls/tool) box. CSV summaries keep
full per-tool detail.sampled=False and sample_count = the full latency_count for every tool
(previously the two highest-volume tools, exec_command and Bash, were reservoir-sampled).plot.py is a thin query→shape→plot pipeline over the shared trace DuckDB:
_per_tool_query(plot_name_expr, *, by_provider) — the shared per-tool aggregation: normalizes the
tool name (blank/NULL → <unknown-tool>), applies the effective-latency precedence, and emits per
bucket the call/latency_count/missing_latency/nonpositive_latency/error_calls counts,
latency_sum/min/max, the exact list(eff) of positive latencies, and a first-appearance
first_seen ordinal. plot_name_expr selects the raw name (CSV) or the mcp_*→mcp alias
(figure); by_provider splits per rounds.provider.load_tool_stats(con) — global {tool_name: ToolStats} for the summary CSV (raw names, no
collapsing), inserted in first-appearance order so the stable sort(key=calls) reproduces the old
dict-order tie-break.load_tool_stats_by_provider(con, *, min_calls) — per-provider stats for the boxplot with the MCP
merge in SQL, then the rare-tool collapse in Python; real tools are inserted in alphabetical
plot-name order (the old merged-dict order) with Other appended last, pinning equal-call ties.load_tool_latency_values_by_provider(con) — {provider: [positive latency, …]} feeding both
CDFs (exact, no reservoir).load_tool_latency_bins(con, *, by_provider) — the 8 coarse TOOL_LATENCY_BINS_MS half-open bins
(call/error counts + summed latency), global and per-provider.plot_* / write_* — the four figures and four CSVs.main() — wires the standard trace_db CLI (--db | -i/--input | -o/--output-dir) and embeds
the self-contained PNG sidecar.The matplotlib 3.9 labels→tick_labels boxplot-kwarg rename is handled by the _BOXPLOT_LABEL_KW
shim so the figure also renders under the matplotlib 3.8.x bundled with Pyodide (the web Analyze
tab). The data layer (parsing, surrogate keys, schema) lives in artifacts/utils/trace_db.py; see
artifacts/utils/DB_SCHEMA.md.
# default merged trace, output next to this README
uv run python artifacts/tool_calls/tool_latency_distribution/plot.py
# a specific trace (materialized to a temp DuckDB cache on first use)
uv run python artifacts/tool_calls/tool_latency_distribution/plot.py -i trace/sample.jsonl
# a prebuilt DB (run_all.py's build-db step passes this), into a chosen dir
uv run python artifacts/tool_calls/tool_latency_distribution/plot.py --db "$TMPDIR/trace.duckdb" -o "$TMPDIR/out"
Useful flags: --top-tools (max boxes per panel, default 30), --min-tool-calls-for-plot
(rare-tool collapse threshold, default 20).
Written to -o (default this folder):
tool_latency_by_tool.png — per-provider box/whisker panels of per-call latency by tool.tool_latency_summary.csv — full per-tool stats (raw names): calls, latency_count,
missing_latency, nonpositive_latency, error_calls, mean_ms, min_ms, p50/p90/p99_ms,
max_ms, sample_count, sampled, providers.tool_latency_weighted_bins.png / .csv — tool-call count vs summed-latency share over the 8
coarse latency bins.tool_latency_count_cdf_by_provider.png / .csv — cumulative tool-call count ≤ a latency
threshold, per provider.tool_total_latency_cdf_by_provider.png / .csv — cumulative summed latency from calls ≤ a
threshold, per provider.Each PNG is self-contained — it embeds this README, the CSVs, and the plotting code. Unpack with
uv run python artifacts/utils/png_sidecar.py extract <png>.