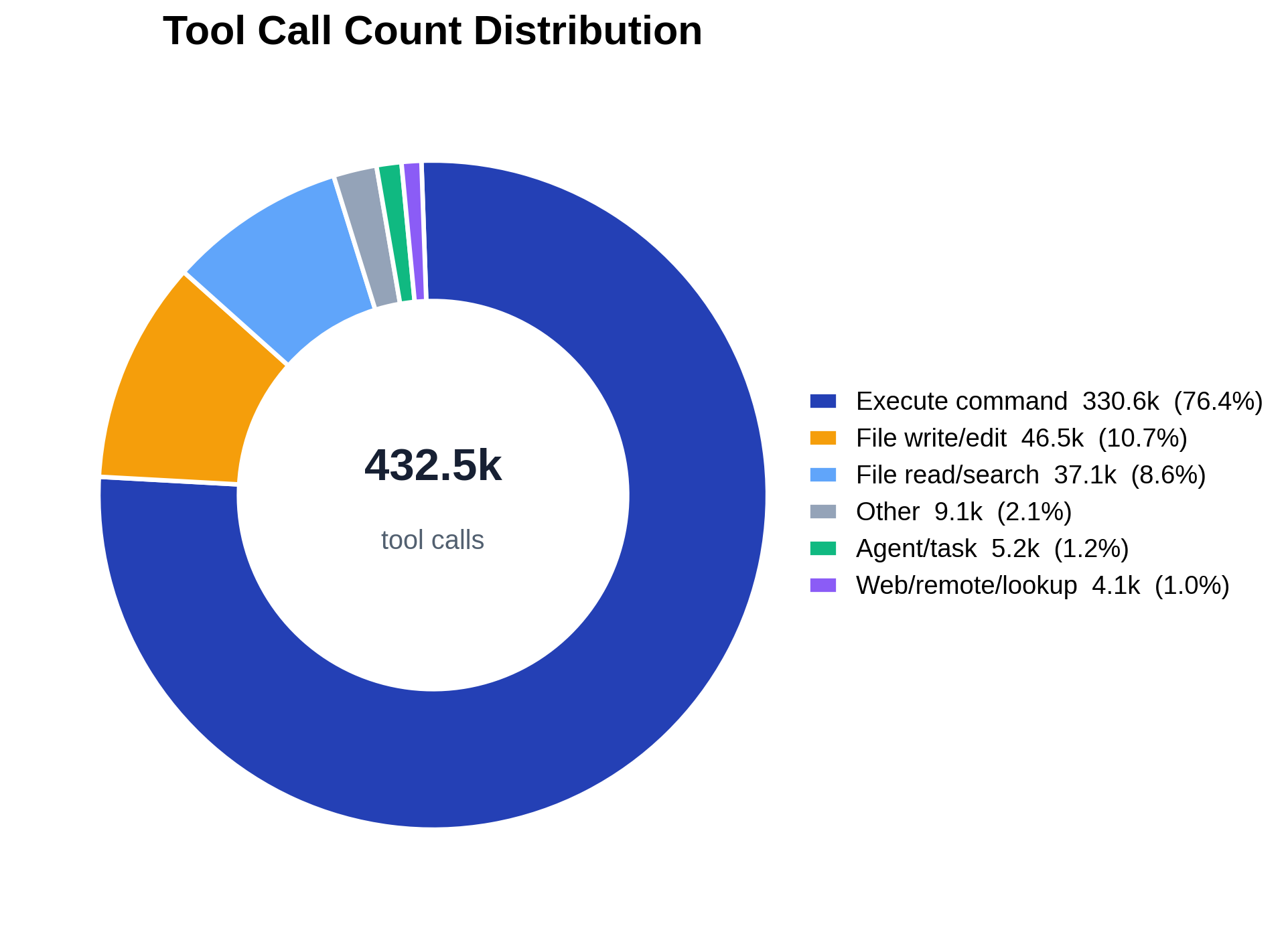
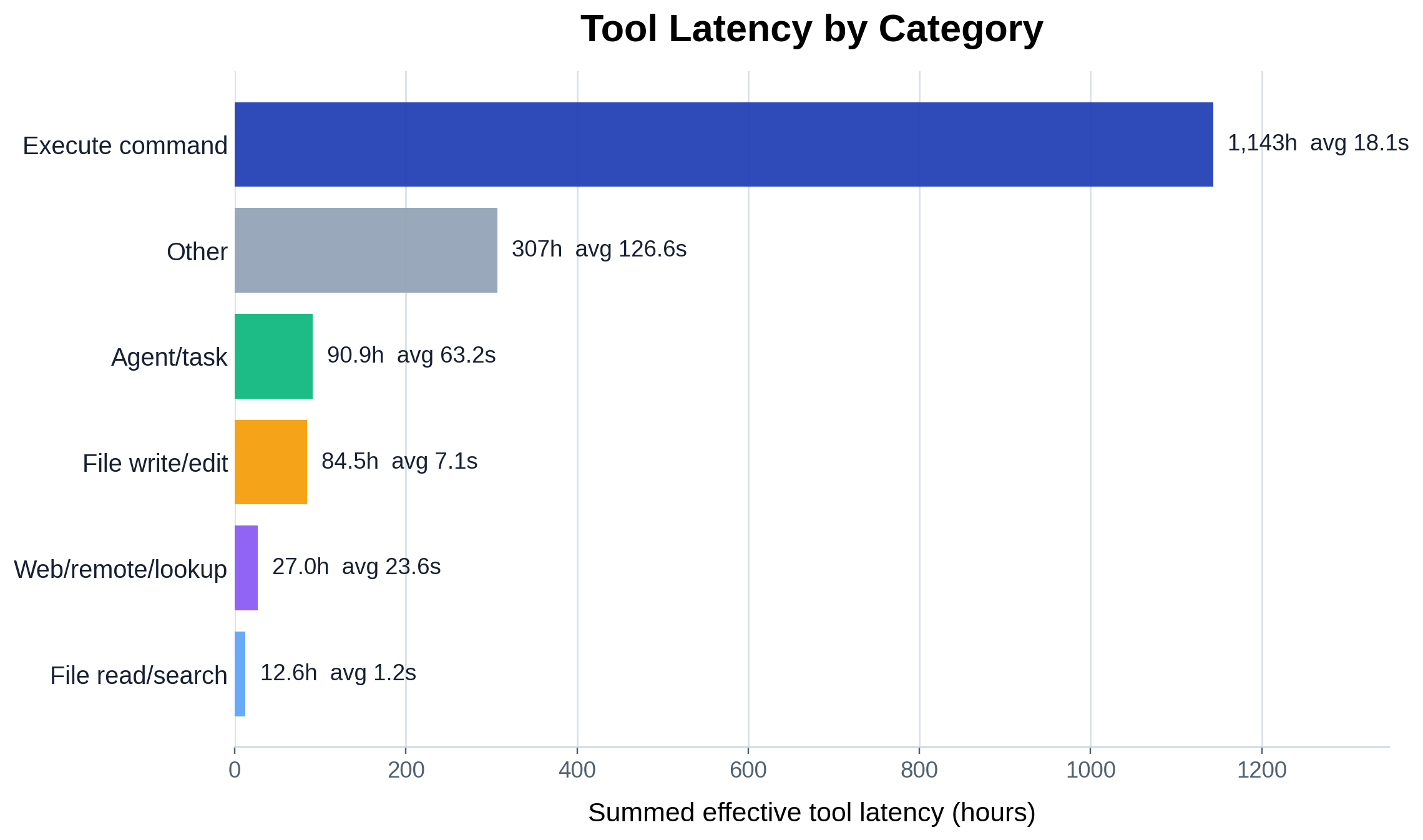
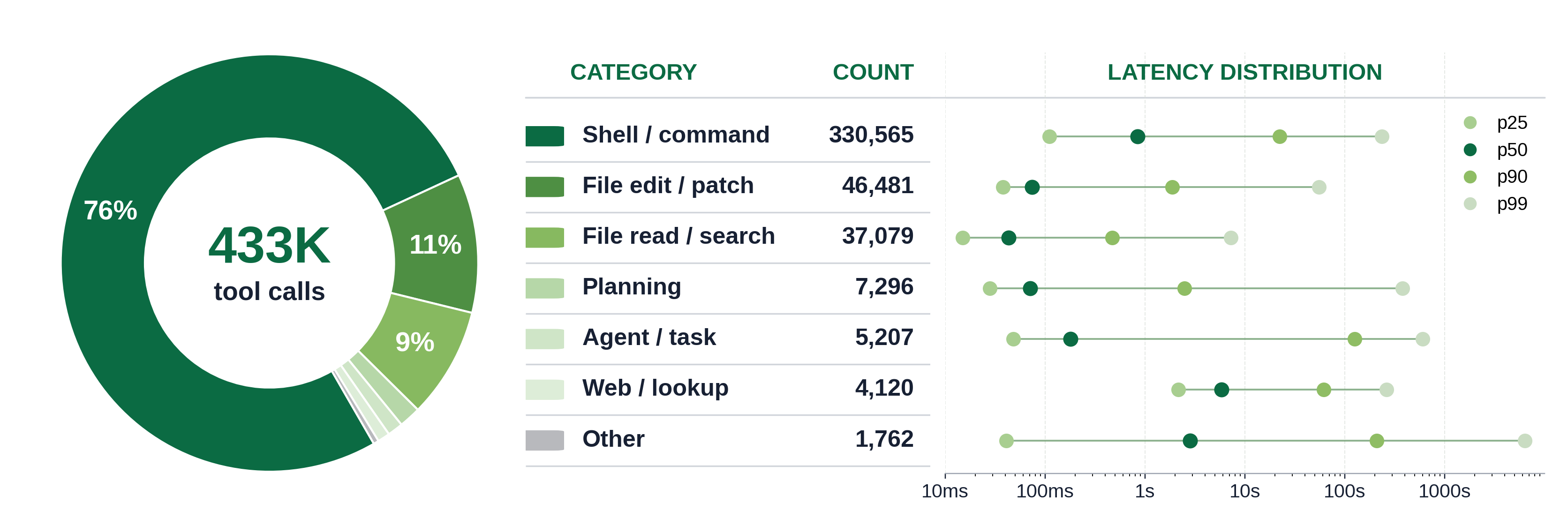
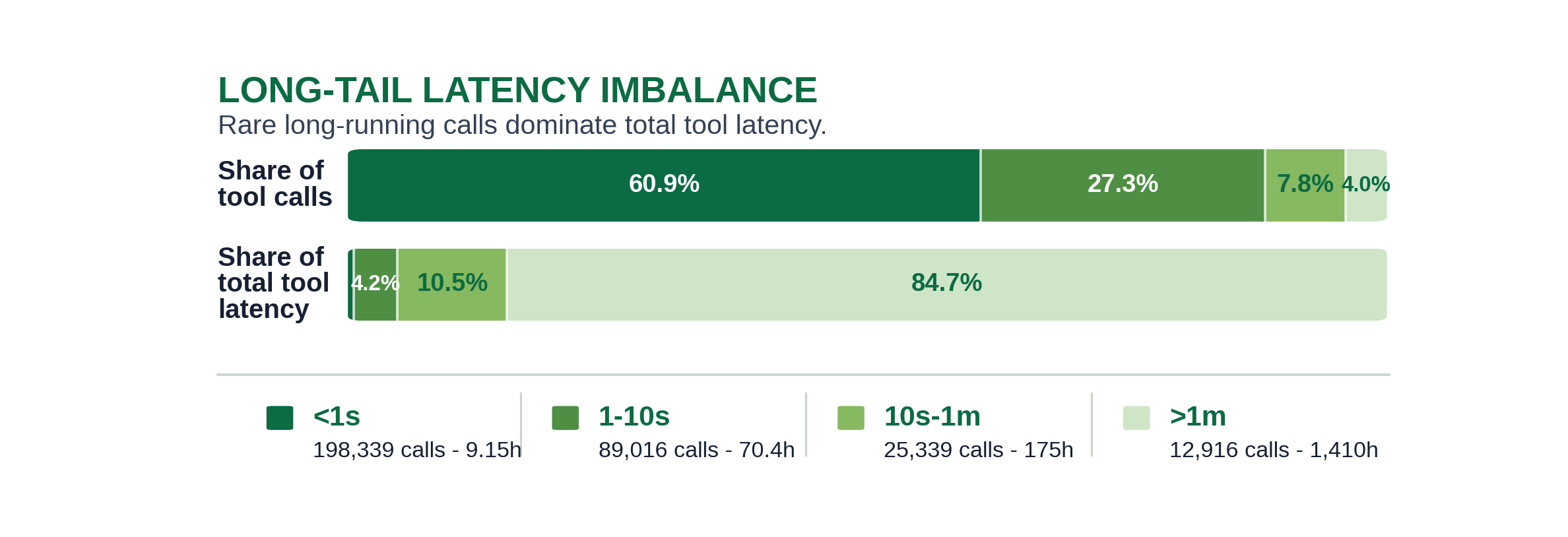
Re-ranking the same categories by summed effective latency (hours) tells a different story than
the count ring, because per-call cost varies by more than two orders of magnitude (each bar is
annotated with average seconds per call). Execute-command leads at ~1,826h, while agent/task
averages ~43s per valid call (128h total) and web/remote/lookup ~16s (33.5h). The Other bucket
punches far above its 4.3% call share at ~968h (~109s average). File read/search, despite being
the third-most-called category, costs only ~17.8h at ~0.93s per valid call.
That is the count-vs-cost gap: cheap high-frequency primitives versus expensive, rarer calls that
block on real work or the user.