An idealised, per-step binary model (the paper’s rule): a step’s prefix is a full hit if the
idle gap before it is <= tau, and a full miss (re-prefilled) if the gap is > tau.
Per session step S, paired with its predecessor P, with idle gap g before S (human think
time for a user step; tool latency for a tool-result step):
L = prefix_tokens + newly_append_tokens — total prompt tokens at S.fresh = clip(max(0, L - L_prev) - output_tokens(P), 0, append) — the truly new user/tool tokens
(context growth minus the prior step’s output; same definition as redundant_prefill, and
output_tokens already includes reasoning per trace_facts/overview_summary). fresh is the
irreducible prefill the cache can never serve.cacheable = L - fresh — reusable tokens a perfect, eviction-free cache would serve.
This is an idealised cache whose only imperfection is the eviction timeout: a retained step
(gap <= tau) prefills only its fresh tokens, an evicted step re-prefills its whole context L.
Two token-weighted quantities over all covered steps:
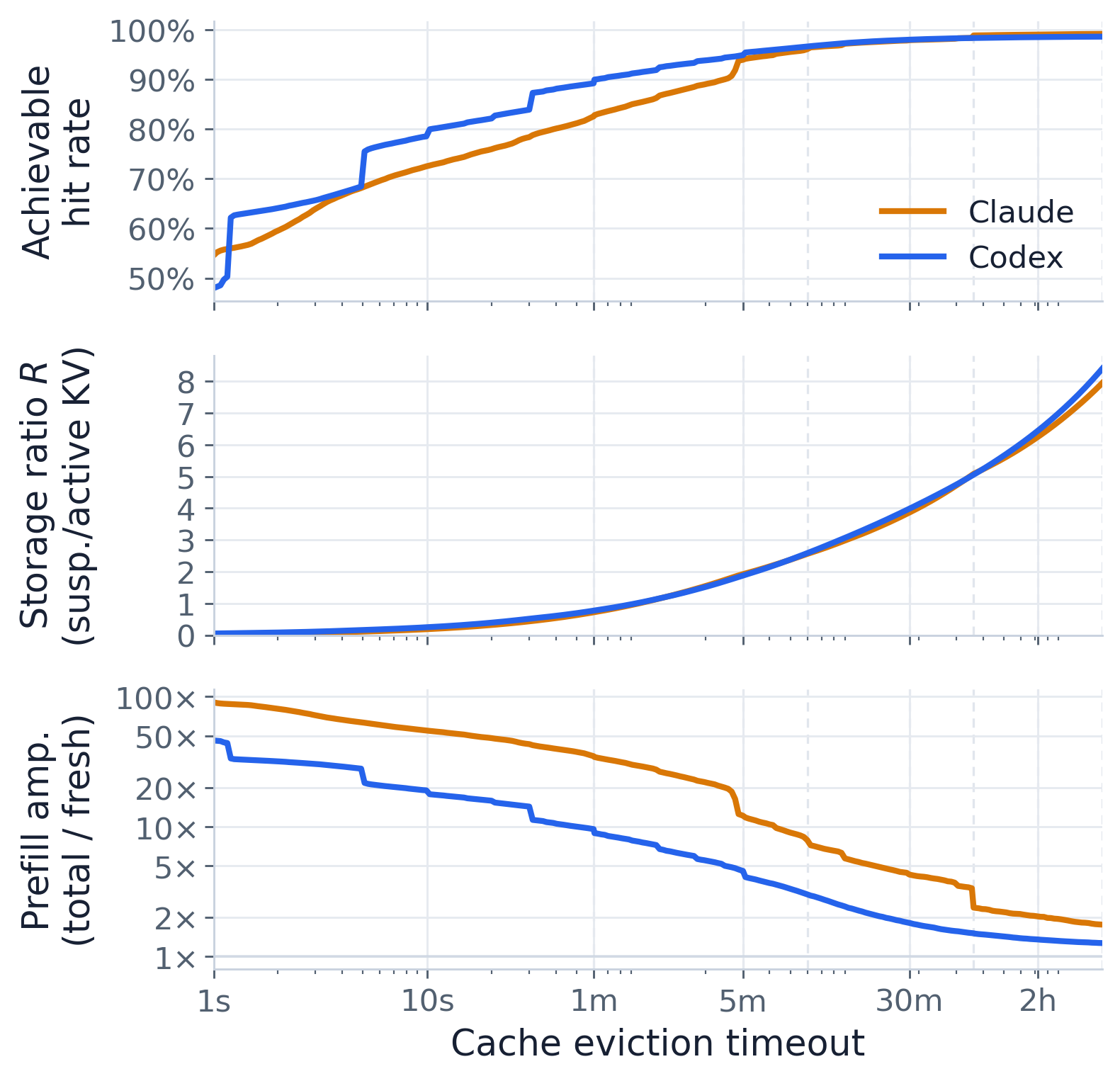
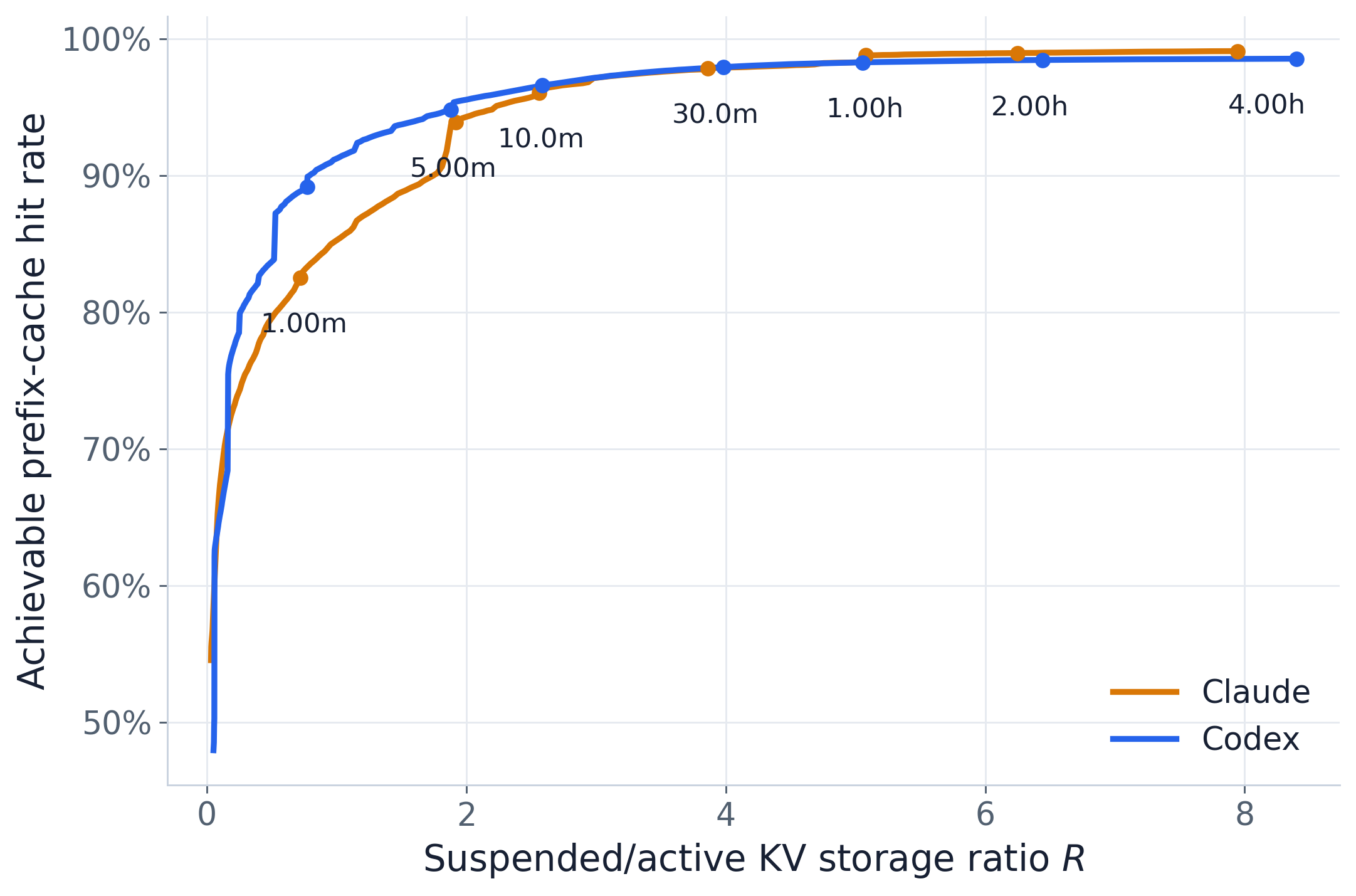
hit_rate(tau) = sum_{g<=tau} cacheable / sum L (-> 1 - fresh/L = optimal as tau->inf)
prefill(tau) = sum fresh + sum_{g>tau} cacheable (tokens prefilled at tau)
A(tau) = prefill(tau) / sum fresh (prefill amplification; floors at 1x)
redundant_ratio(tau)= 1 - 1 / A(tau) (equivalent share-of-prefill form)
Prefill amplification A is the bottom panel: how many times more tokens are prefilled than the
irreducible fresh minimum. An eviction-free perfect cache prefills only fresh, so A floors
at 1x; tighter eviction re-prefills evicted context and inflates it.
The real deployed cache is overlaid as a reference (it is not the idealised model): it prefills
append (amplification sum append / sum fresh) and serves prefix (hit sum prefix / sum L).
That operating point lands on the idealised curve at the effective eviction time --- the tau
where the idealised hit rate equals the real one. This is how the section reconciles with the static
redundant_prefill table (whose 1 / (fresh % of append) is the real amplification).
Storage axis (capped). Idle is capped by the eviction time: before tau elapses you cannot
know a gap will outlast it, so the KV is held to tau regardless. With gen_r the per-round
input->last-output span (active decode time),
R(tau) = sum_i min(g_i, tau) / sum_r gen_r (suspended-KV / active-KV storage ratio)
kv_active_ratio(tau)= 1 / (1 + R(tau))
This R is the corrected storage ratio from the paper’s §7.5 derivation (R = (T_human + T_tool) / T_generation): idle time dwarfs generation time, so suspended KV dominates and R grows well above
1 at long timeouts.
Method and assumptions:
- Gaps reuse
cache_hit_idle_relationship: a user step’s gap is first_activity - previous_round.last_activity; a tool-result step’s gap is the max leading tool-result
duration (the request’s wall idle while its tools run, which is what suspends its KV — note this
differs from kv_cache_active_ratio, which sums every individual tool-call latency).
- Generation span reuses
kv_cache_active_ratio’s input->last-output definition.
- Coverage. A step counts only when it has a predecessor (for
fresh) and a measurable idle
gap; session-first and gap-less steps are excluded. The hit rate is token-weighted over the
covered steps, so it is an achievable-cache estimate, not the observed system hit rate.
- Independence. Each step’s eviction is decided by its own gap; cascade effects (an eviction
shrinking later steps’ reusable context) are not modelled — matching the paper’s binary rule.